ソーシャル経済メディア「NewsPicks」の高山です。
NewsPicksではユーザーが画面上で操作したときなどに行動ログを記録し、それを分析してサービスの改善に役立てています。
そのログはWebサーバーのnginxで記録されてデータウェアハウスであるAmazon Redshiftに送られるのですが、僕はそのRedshiftまわりのチームを少し前まで持っていました。
今回は、当時おこなった、ログの増減アラートの仕組みについて書いていきます。
何が課題だったか
行動ログの記録処理は、開発者が画面上で確認するわけではないので、エンバグしたままリリースされやすい箇所です。
NewsPicksでも過去に何度もログの記録が止まってしまったり、異常に多くのログが出ていたりしたことがあり、そのたびに集計コードを直したり復旧したりと大変な労力を割いてきた歴史があります。
しかも、バグが起こってから気づくまでに何日も、あるいは何週間、何ヶ月もかかることがある上に、バグって記録されたという事実はその後もずっと引きずってしまう、たちの悪い性質のバグになります。
例えば、経営判断のためのグラフを表示するときに、「2024年2月〜4月はログが異常だったので無視してください」などと但し書きがずっとついて回ります。
過去にあったアラートの仕組み
過去にはAWS Lambdaでこのような通知を送っていたことがあります。
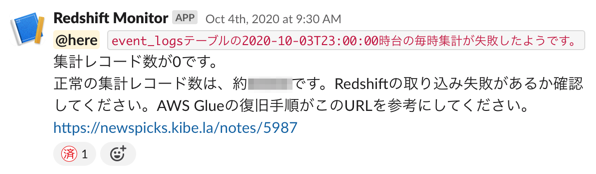
時間あたりのログの数が決め打ちした閾値を下回ったら通知する方法で、主にETL処理の失敗に気づくために使っていました。
課題
上記の通知ではイベントログの数を監視していますが、分析担当者から「最近iOSアプリの特定のイベントが普段よりも少ない」のような指摘を受けることが多くあり、そのようなケースに分析担当者よりも前に気づくことができていませんでした。
しかし、この時は通知を変更したり追加する時にLambdaをデプロイしなければならず、これ以上に充実させることができていませんでした。
スマートに解決しようとして導入して失敗した仕組み
そこで導入したのが、次のような通知でした。
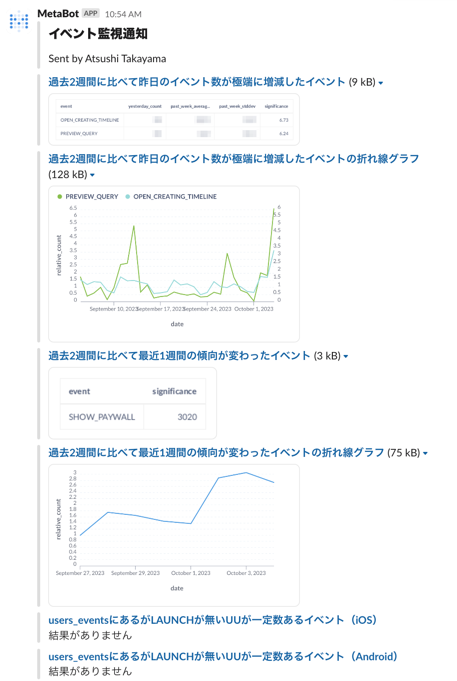
SQLの集計関数を使ってちょっとした統計処理をしています。例えば、過去2週間分のイベント数の平均値と標準偏差を出して、昨日のイベント数が平均値から標準偏差の5倍(いわゆる5σ)乖離していたら通知するなどです。
それをMetabaseというOSSのBIツールのSlack通知機能で通知して、ぱっと見で異常かどうかがわかるようにグラフまで付けていました。このような通知が簡単に作れるMetabaseは本当に素晴らしいソフトウェアです。
また、調査用には、アプリ(iOS, Android, Web)のバージョンごとに特定のログの数を可視化するようないい感じのダッシュボードも用意していました。実際にその画面をアプリの開発者に送って、エンバグに気づいたこともありました。
課題
この仕組みは一見良さそうではあったのですが、正しく異常を検知できるような閾値の作り込みができずに、結果として誤検出が多くなり、調査しきれなくなってしまいました。
普段のイベント数が少なすぎる場合は無視したり、3σを5σに変えたりなどはしたのですが、多くの種類のログがあるため、誤検出率が低かったとしても毎日数件は出てしまいますし。逆に誤検出を減らそうとしたら本当の異常が検出できなくて困ることになりかねません。
もう一つの課題としては、この通知を受け取るのがデータ基盤のチームで、ログ記録処理はアプリ開発のチームというふうに、チームが分かれていたため、どうしても調査に時間がかかってしまっていたことです。アプリ開発者であれば、最近自分が変更した処理のログがアラートで出ていたらピンときますし、誤検出であればすぐに無視することもできます。しかし、データ基盤のチームで一旦調査してアプリ開発のチームにメンションするというステップにしていたことで最適ではない形となっていました。
現在の仕組み
これまでの試行錯誤を経て、現在のアラートはこちらです!
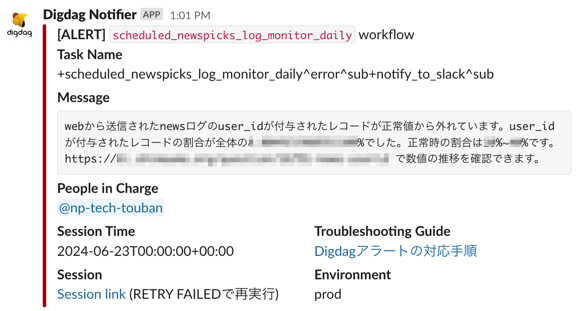
なんとなく、元に戻っているように見えますね!
違うところは、現在の仕組みは変更するのが遙かに簡単ということです。設定ファイルをGitHubでプルリクしてマージされれば自動デプロイされますので、エンジニアメンバーであれば誰でもできる手軽さです。(この記事の末尾にコードを載せておきます)
また、最近ではアプリ側の自動テストでログ記録処理のバグを検知するようになったことも背景としてあります。重要なのはアプリ開発者がコードを書いたら自分ですぐにバグに気づけることだったのです。
このように開発組織全体でログ周りの取り組みを行った結果、データ基盤に入るログのアラートは、クライアントサイドアプリ以外に起因するバグを検知したり、ビジネス的に絶対に担保したい重要なログの正しさを保証するようなものに絞ることにしました。
おわりに
NewsPicksではこれまで数々のログ周りの失敗を経て、「ログは大事」を合言葉に品質向上に取り組んでいるところです。
Software DesignでNewsPicks開発メンバーで執筆している「ぼくらの『開発者体験』改善クエスト」という連載の「データに基づく意思決定と開発者体験」という記事でも、他の様々な取り組みについて書いていますので、興味があれば読んでみてください。(僕も執筆に関わった記事です!)
付録:digdagとSQLによるSlack通知の仕組み
SQLでSELECTして、閾値から外れていたらSlack通知するコードを載せておきます。上に貼り付けたスクリーンショットの箇所から抜粋してきたものです。
digdagの.digファイル(YAML)でこのように記載しています。
+monitor_xxxxxx: +query: redshift>: xxxxxx.sql store_last_results: first +fail_if_out_of_threshold: if>: ${redshift.last_results.rate <= … || redshift.last_results.rate >= …} _do: fail>: ○○が正常値から外れています。××の割合が全体の${redshift.last_results.rate}%でした。正常時の割合はxx%~xx%です。https://example.internal で数値の推移を確認できます。 ... _error: _export: workflow_name: scheduled_newspicks_log_monitor_daily call>: ./notify_slack.dig
redshift> はdigdadに組み込みのオペレーターです。
.sqlファイルの中では select ... as rate from と書いてあり、 store_last_results: first というおまじないによって.digファイルから redshift.last_results.rate という変数としてアクセスできるようにしています。(これも上のドキュメントページに載っています)
if> _do の分岐や fail> というのもdigdagの標準機能です。
fail> で失敗させたワークフローは、下の _error で捕まえられ、 call>: ./notify_slack.dig でSlack送信の共通処理に入ります。
./notify_slack.dig ではSlackに送るペイロードを環境変数に詰め込んだりなどした後に、このようなことをしています。先ほど fail> のところに書いたメッセージは、この段階では message というdigdagの変数として参照できるようです。
+notify_to_slack: if>: ${notification.slack.is_available} _do: slack>: ./configs/slack_payload_template.yml
この slack> オペレーターは digdag-slack というOSSのdigdagプラグインを使っています。 ./configs/slack_payload_template.yml の内容は割愛しますが、プラグインのREADMEを見るとイメージが掴めるかと思います。
以上のように、ワークフロー失敗時の共通のSlack送信処理があるので、それに乗っかる形でSQLを使ってクリティカルなログの状態を監視しています。監視項目を追加するときにはSQLとYAMLを少し書くぐらいの作業で完結するという紹介でした。