こんにちは。SPEEDA 開発チームの old_horizon です。
JVM アプリケーションの運用について回るのが、OutOfMemoryError (以下 OOM) への対処です。
しかし実際に発生した際に、適切なオペレーションを行うのは意外と難しいのではないでしょうか。
特に本番環境では、まず再起動して復旧を急ぐことも多いかと思います。しかし、ただそれを繰り返すばかりでは原因がいつまでも特定できません。
今回は Kubernetes で運用する JVM アプリケーションに対して、ダウンタイムを抑えつつ調査に役立つ情報を自動的に収集する仕組みを構築してみたいと思います。
環境構築
実際に構築してみたサンプルを、こちらのリポジトリに用意しました。
https://github.com/old-horizon/k8s-oom-sample
動作確認は以下の環境で行っています。
- Ubuntu 18.04
- MicroK8s 1.18.6
clone して kubectl apply -f kubernetes/ を実行すると oom-sample ネームスペースに各種リソースが作られます。
(おそらく初回は途中で失敗するため、二度実行してみてください)
次章より、このサンプルを使って解説を進めていきます。
OOM 発生時に、自動的にヒープダンプを取得しコンテナを再起動する
ヒープダンプがあれば、Eclipse Memory Analyzer 等で解析してリークしていたオブジェクトを特定できます。
しかし OOM で処理が長時間滞留した場面では、さらに復旧を遅らせてまでダンプを取得するのに抵抗を感じ、再起動を優先させることもあるかと思います。
とはいえ通知を受けて手動で対応している限り、多少なりとも遅延は発生しているわけです。この際すべて自動化して、焦らなくてもユーザーへの影響が最小限に収まるようにしましょう。
java コマンドのオプション指定
Dockerfile (ktor-oom/Dockerfile) で、java コマンドに次のオプションを指定しました。
-XX:+ExitOnOutOfMemoryError
OOM 発生時に JVM が終了する-XX:+HeapDumpOnOutOfMemoryError
OOM 発生時にヒープダンプを出力する-XX:HeapDumpPath
-XX:+HeapDumpOnOutOfMemoryErrorによるヒープダンプの出力先を指定する
JVM が終了すると、Kubernetes の自己修復機能によりコンテナが再起動されます。
補足
ヒープダンプは
java_pid(プロセス ID).hprofのファイル名で出力されます。
なお同名のファイルがすでに存在する場合は上書きされません。
コンテナ環境の場合、プロセス ID が常に一定ゆえファイル重複が起きやすいためご注意ください。-XX:OnOutOfMemoryErrorで OOM 発生時に任意のコマンドを実行できます。
上記のオプションと併用可能です。
ヒープダンプ出力先のボリュームをマウント
ヒープダンプは Pod が存在する間のみ存続する emptyDir ボリュームに出力します。
Dockerfile (ktor-oom/Dockerfile) で、ヒープダンプ出力先に /dump を指定します。
-XX:HeapDumpPath=/dump
Deployment (kubernetes/ktor-oom.yml) で /dump にボリュームをマウントします。
volumeMounts: - mountPath: /dump name: dump-volume volumes: - name: dump-volume emptyDir: {}
これにより、コンテナ再起動前に出力されたダンプが取得できるようになります。
readinessProbe によるヘルスチェック
コンテナの再起動直後は、リクエストを処理できない場合があります。
readinessProbe で正しく処理できる状態になったことを確認してから、Service のルーティング対象に復帰するようにします。
Deployment (kubernetes/ktor-oom.yml) より抜粋
readinessProbe: httpGet: port: 8080 path: /v1/ping
レプリカ数の確認
基本的なことですが、常に使用可能な Pod が複数存在するようにしましょう。
今回はサンプルなのでレプリカ数は 2 にしています。
Deployment (kubernetes/ktor-oom.yml) より抜粋
spec: replicas: 2
Prometheus + Grafana で JVM のメトリクスを可視化する
ライブラリ・フレームワークの設定ミスによるリークは、ネット上にも情報が多いためヒープダンプの解析結果から比較的特定しやすい印象があります。
一方で社内で実装したプロダクションコードでリークが起きている場合、先人の知恵に頼ることはできません。
そのため地道にコードを読む必要はありますが、ヒープ使用量の推移からリークが疑われる事象が発生するタイミングを特定できれば、調査範囲を絞ることができます。
そこで Prometheus + Grafana により JVM のメトリクスを可視化して、その記録をもとに疑うべきポイントに目星がつけられる状況を目指します。
JVM アプリケーションの Java agent に JMX Exporter を指定する
JMX とは
JVM アプリケーションでは、JMX (Java Management Extensions) という監視・管理フレームワークが利用できます。
以下に例を挙げますが、標準でかなり多くの指標を取得することができます。
- 領域ごとのメモリー使用量
- ロード済みクラス数
- スレッド数
JMX から取得できた情報を Prometheus で収集するには、所定のテキストフォーマットに変換して HTTP で配信する必要があります。
今回アプリケーション本体には手を加えず、実行時にこの機能を追加するために Java agent を使います。
Java agent とは
Java agent は J2SE 5.0 で java.lang.instrument パッケージと同時に追加された仕組みです。
Javadoc によると、正式名称は「Javaプログラミング言語エージェント」といったところでしょうか。
-javaagent:(エージェント JAR ファイルへのパス) を指定して java コマンドを実行すると、main に先んじてエージェント JAR ファイル内の premain が呼び出されます。
このタイミングでバイトコード操作が可能になるため、AspectJ の動的ウィービングなどで利用されています。
いわゆる黒魔術を実現するための仕組みですが、応用することでアプリケーションの起動前に任意の処理を差し込むことができます。
Dockerfile の編集
Prometheus が提供する JMX Exporter を Java agent に指定してアプリケーションを起動します。
するとアプリケーションの main 実行前に、指定されたポートで JMX メトリクスを公開する HTTP サーバーが立ち上がります。
まずは JAR ファイルをダウンロードし、設定ファイルである config.yaml を作成します。
今回の用途ではデフォルト設定で問題ないため、中身は空のままです。
ADD https://repo1.maven.org/maven2/io/prometheus/jmx/jmx_prometheus_javaagent/0.13.0/jmx_prometheus_javaagent-0.13.0.jar . RUN touch config.yaml
最後に java コマンドで Java agent を指定してアプリケーションを起動します。
-javaagent:./jmx_prometheus_javaagent-0.13.0.jar=9100:config.yaml
これで 9100 ポートで JMX メトリクスが公開されました。
詳細は Dockerfile (ktor-oom/Dockerfile) をご覧ください。
Prometheus の Service Discovery で動的に監視対象を指定する
Service Discovery について
Prometheus は、自身が監視対象からデータを収集する Pull 型アーキテクチャを採用しています。
したがって、基本的には監視対象への接続情報をあらかじめ知っておく必要があります。
しかし Kubernetes で運用するアプリケーションの場合、自動的に Pod のスケールや再配置が行われるため接続先を静的に定義しておくことはできません。
このように接続先が動的に変わる場合には、Service Discovery が便利です。
その名の通り、Prometheus 自身が監視対象を検出する機能です。Kubernetes の他にも Azure VM, AWS EC2, GCP GCE といった主要なクラウド仮想マシン等に標準で対応しています。
Kubernetes の設定
まずは、アプリケーションの Service (kubernetes/ktor-oom-svc.yml) に任意のアノテーションを付与します。
サンプルで使用したアノテーションの用途は次のとおりです。
prometheus.io/java_scrape
メトリクスを取得する対象の場合は trueprometheus.io/java_port
メトリクスを公開しているポート番号を指定
annotations: prometheus.io/java_scrape: 'true' prometheus.io/java_port: '9100'
アプリケーション本体 の 8080 に加え、メトリクスの 9100 ポートも忘れずに公開します。
ports: - name: app protocol: TCP port: 8080 - name: metrics protocol: TCP port: 9100
同様に、Deployment (kubernetes/ktor-oom.yml) でも両方のポートを公開します。
ports: - containerPort: 8080 - containerPort: 9100
Prometheus の設定
先ほど付与したアノテーションを持つ Service 配下の Pod を監視対象として設定します。
今回は Kubernetes クラスタ内に Prometheus を立てましたが、認証情報を設定すればクラスタ外からも監視できます。
デフォルト設定の場合、Prometheus は /etc/prometheus/prometheus.yml を設定ファイルとして参照します。
サンプルでは ConfigMap の形式で Pod にマウントしているため、内容は (kubernetes/prometheus-config.yml) に記載されています。
以下、その一部を抜粋しながら解説していきます。
role が監視対象を検出する際のルールです。
endpoints を設定したことで Service のルーティング先であるバックエンドが対象になりました。
kubernetes_sd_configs: - role: endpoints
続いて relabel_configs のブロックに入ります。
role: endpoints により、Prometheus は Kubernetes クラスタ上のすべての Service に紐づくバックエンドを検出します。
しかし実際に監視したい対象は一部のため、条件を指定して絞り込んでいく必要があります。
Prometheus は検出した候補から取得できるメタデータを、ラベルとして扱うことができます。
このラベルを元にしてフィルタしたり、値を設定したりすることで必要なものだけが抽出されるようにします。
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_java_scrape] action: keep regex: true
アノテーション prometheus.io/java_scrape の値が、正規表現 true に一致した場合は候補に残ります。
一致しなければ、この段階で除外されます。
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_java_port] action: replace target_label: __address__ regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2
まずメトリクス取得先ホストが入った __address__ と、アノテーション prometheus.io/java_port の値を区切り文字 ; で連結します。
対象の Service は 2 つのポートを公開しているため、監視対象は Pod ごとに 8080 と 9100 の 2 つがヒットします。
したがって、ここまでの出力は (Pod の IP):(8080 または 9100);9100 になります。
次に正規表現 ([^:]+)(?::\d+)?;(\d+) でマッチさせ、$1$2 で置換した値を __address__ に設定します。
よって __address__ は (Pod の IP):9100 に上書きされ、正しく監視先 URL が組み立てられるようになりました。
このルールは __address__ に含まれるポートが 8080 でも 9100 でも同じ値を返すため、その結果 9100 だけが監視対象に残ります。
Grafana にダッシュボードを作成する
JMX Exporter の出力に対応する JVM dashboard を使用しました。
サンプルでは grafana-init ジョブにより、自動的にダッシュボードが追加されるようにしています。
簡単なシェルスクリプトで実現していますので、もし興味があれば kubernetes/grafana-init-config.yml をご覧ください。
動作確認
それでは、サンプルの動作確認を進めていきましょう。
なお MicroK8s 前提での手順になりますので、異なる環境をお使いの方は適宜読み替えてください。
まずは Kubernetes クラスタ内のアプリケーションにアクセスするための InternalIP を取得します。
$ kubectl get nodes -o jsonpath='{.items[*].status.addresses[?(@.type=="InternalIP")].address}'
192.168.0.11
各アプリケーションの Service は NodePort であり、ランダムに割り当てられたポートでクラスタ外に公開しています。
以下は prometheus-svc のポートを取得した例です。
$ kubectl -n oom-sample get svc prometheus-svc -o jsonpath='{.spec.ports}'
[map[nodePort:31122 port:9090 protocol:TCP targetPort:9090]]
上記より、Prometheus にアクセスするための URL は http://192.168.0.11:31122 であることが確認できました。
他のアプリケーションに接続する場合も、この要領で URL を取得してください。
JMX メトリクスの取得
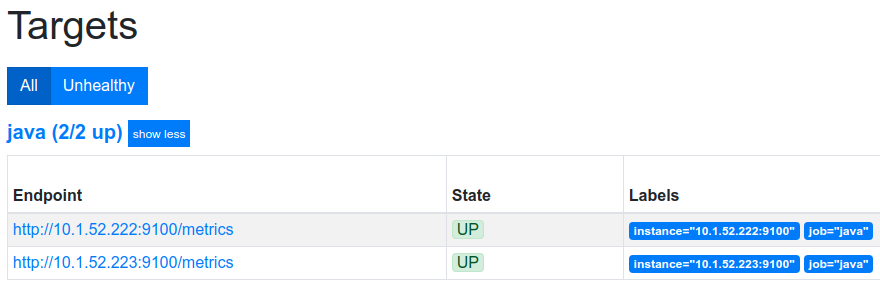
Prometheus にアクセスして、画面上部メニューの Status > Targets を選択します。
以下のように、2 台の Pod それぞれが監視対象として認識されています。
次に Grafana を開きます。ユーザー名およびパスワードは admin です。
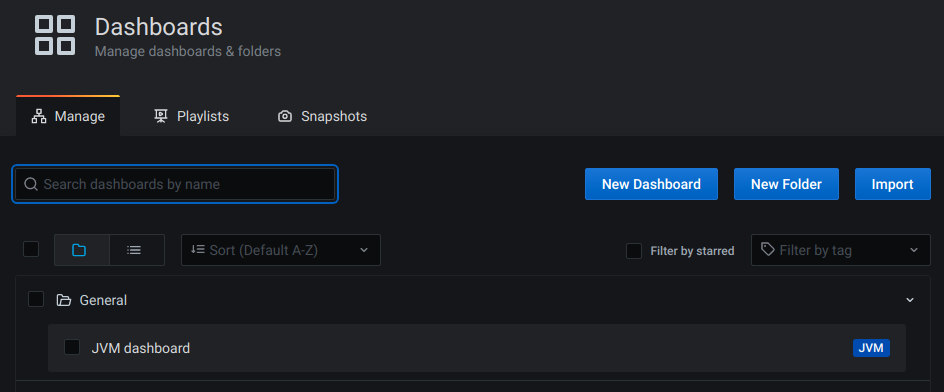
画面左メニューから Dashboards > Manage を選択すると、表示された一覧に JVM dashboard が存在しています。
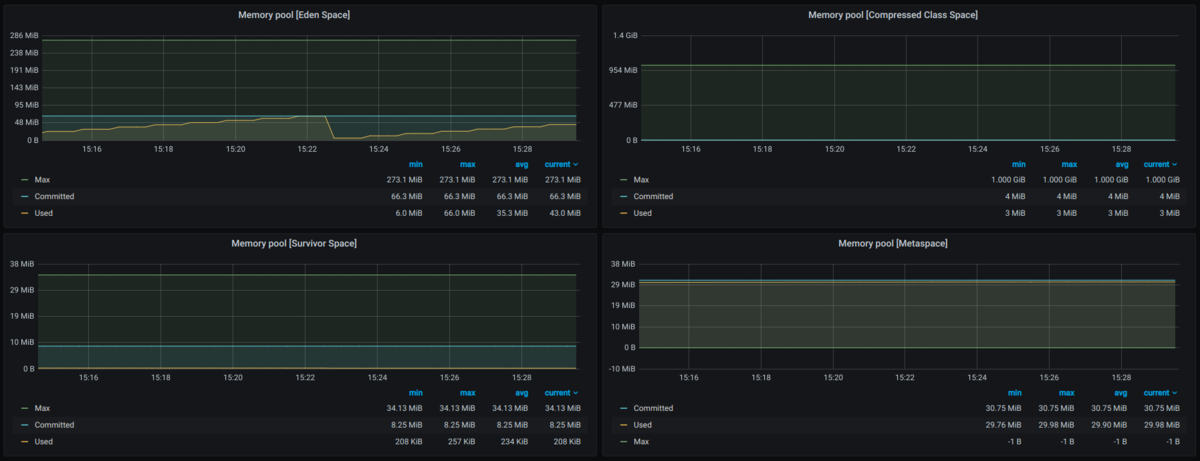
実際に表示してみると、グラフ形式で値の推移が確認できることがわかります。
OOM を発生させてヒープダンプを取得してみる
サンプルアプリケーション (ktor-oom) は、/v1/oom にアクセスすると OOM が発生する実装になっています。
ここにリクエストして、構築した仕組みが動作することを確かめます。
最初に現在の Pod の状態を見てみます。
まだコンテナは一度も再起動していないため RESTARTS は 0 のはずです。
$ kubectl -n oom-sample get po -l app=ktor-oom -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES ktor-oom-646544cc67-4x9bd 1/1 Running 0 42m 10.1.52.222 t470s <none> <none> ktor-oom-646544cc67-ljgpt 1/1 Running 0 42m 10.1.52.223 t470s <none> <none>
どちらの Pod も /dump にファイルは存在しません。
$ kubectl -n oom-sample exec ktor-oom-646544cc67-4x9bd -- ls /dump $ kubectl -n oom-sample exec ktor-oom-646544cc67-ljgpt -- ls /dump
それでは OOM を発生させてみましょう。
以下のコマンドで /v1/oom と /v1/ping に連続してアクセスします。
/v1/ping のリクエストは正しく処理されたため、OOM が発生した Pod はルーティング対象から外されたことがわかります。
$ curl -v http://192.168.0.11:31072/v1/{oom,ping}
* Trying 192.168.0.11...
* TCP_NODELAY set
* Connected to 192.168.0.11 (192.168.0.11) port 31072 (#0)
> GET /v1/oom HTTP/1.1
> Host: 192.168.0.11:31072
> User-Agent: curl/7.58.0
> Accept: */*
>
* Empty reply from server
* Connection #0 to host 192.168.0.11 left intact
curl: (52) Empty reply from server
* Connection 0 seems to be dead!
* Closing connection 0
* Hostname 192.168.0.11 was found in DNS cache
* Trying 192.168.0.11...
* TCP_NODELAY set
* Connected to 192.168.0.11 (192.168.0.11) port 31072 (#1)
> GET /v1/ping HTTP/1.1
> Host: 192.168.0.11:31072
> User-Agent: curl/7.58.0
> Accept: */*
>
< HTTP/1.1 200 OK
< Content-Length: 4
< Content-Type: text/plain; charset=UTF-8
<
* Connection #1 to host 192.168.0.11 left intact
pong
再度 Pod の状態を確認すると、片方の Pod の RESTARTS が 1 になっていました。
したがって、この Pod で OOM が発生したものと考えられます。
$ kubectl -n oom-sample get po -l app=ktor-oom -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES ktor-oom-646544cc67-4x9bd 1/1 Running 0 73m 10.1.52.222 t470s <none> <none> ktor-oom-646544cc67-ljgpt 1/1 Running 1 73m 10.1.52.223 t470s <none> <none>
実際にヒープダンプが出力されていることを確認できました。
$ kubectl -n oom-sample exec ktor-oom-646544cc67-ljgpt -- ls /dump java_pid1.hprof
出力されたヒープダンプの回収には kubectl cp が利用できます。
$ kubectl -n oom-sample cp ktor-oom-646544cc67-ljgpt:/dump/java_pid1.hprof ./java_pid1.hprof
おわりに
OOM 発生時に十分な情報が取得できず、再現待ちとなってしまうケースを過去に見てきました。
しかし各種ダンプ・メトリクスがあるだけで調査は大いに捗るため、その取得の自動化は費用対効果が高いと思います。
まさに備えあれば憂いなしです。機会があればぜひお試しください。