概要
ソーシャル経済メディア「NewsPicks」SREチームの中川です。
インフラ部門や予算管理部署にとっては頭の痛い円安時代が到来しました。日々コスト削減の圧が強まっているのは多くの方が実感のことと存じます。
そこで今回はNewsPicksが取り組んだ、若しくは取り組んでいるAWSコスト対策についてまとめました。
全般
何はともあれコストタグ
サービス、IaC管理か手動作成などの要件に関わらずタグをつけましょう。 NewsPicks でもAWSドキュメント通り、リソースの影響度やコストの大きいものから順次タグ付けしていっています。
リソース毎に責任を明確にさせることでコスト意識を持たせ、宙ぶらりんのものが無い様にしていきましょう。
運用における多くのプラクティスと同様に、タグ付け戦略の実装は反復と改善のプロセスです。当面の優先事項から小さく始めて、必要に応じてタグ付けスキーマを拡張してください。
Cost Explorer でリソース別にコストを見よう
CostExplorerの進化が著しいです。 先月のアップデートでリソース別コストがみられるようになったり、詳細な履歴が見れたりするようになりました。 今まではEC2ぐらいしか個別にコスト見られなかったので便利になりましたね。
IaC化しよう
タグを付けようとは言いましたが、リソースが膨大だとタグを手動で付けるのは面倒ですがIaC化するとこういった変更に対応しやすくなります。
NewsPicksでも一部リソースはコード管理されていないので、IaCを推進しています。
もちろん、手動でリソース作る場合でもタグは付けましょう。
QuickSight も使おう
QuickSightとAthenaを組み合わせて Cost Explorer だけでは探知できない、細かい部分もコスト調査することができます。 詳細は以下美濃部さんの記事をご覧ください。
稼働時間対応する際はマスタカレンダを用意したい
休みが不規則な企業もありますので、cron式や人の手だけで開発環境停止とかをやるとどうしても無駄が生じます。 どこかにマスタ用のカレンダを用意・参照しておき稼働時間外は環境停止させるのが理想です。
ちなみにNewsPicksでは GoogleCalender API を使って開発環境を適時シャットダウンさせています。祝日対応もできるので便利です!
これについてもブログで取り上げたことありますので合わせてご覧ください。
コンピューティング、コンテナ関連
EC2
定時バッチはマネージド化しよう
EC2/cronの組み合わせでバッチサーバ運用されてる人も多いとは思いますがこの機会にマネージド化しましょう。
運用していて思うのは、EC2の面倒を見るのは想像以上の労力です。 レガシーなインスタンスタイプであれば頻繁に再起動通知が来ますし、鍵の管理、開発環境であれば起動/停止の手間、など考えたらキリがありません。
上記を鑑み、NewsPicks では StepFunctions、EventBridge、ECS を利用しマネージド化致しました。コスト削減以上に、EC2を管理しなくて良くなったのは大きなメリットでした。
EBS, Snapshot, AMI, EIP を消す
EC2関連のリソースですが、まずはタグ付けやリネームなどで用途をはっきりさせて責任の所在をはっきりさせましょう。
明らかに消されて困るものはタグ付けする等して削除保護し、それ以外のものは担当者やチーム毎に消す消さないの判断をしてもらいます。 あとはスクリプトやスプレッドシートなどでAWS CLIを組んで消してしまいましょう。
NewsPicks では継続的にお掃除をしているおかげでマネコンの画面が大分すっきりしました。
ECS
Container Insights の有効/無効を使い分けよう
ECS、EKSを利用しているとコンテナインサイトを利用する機会があると思います。 コンテナワークロードを良い感じに取得してくれるので重宝する存在ではあるのですが、CloudWatch メトリクスを使用しますのでその分料金がかかります。
どれぐらいの料金かかるかはAWS公式がECSでの利用料金を試算してくれているのでご覧ください。 コンテナインサイトの有効、無効設定はAWS CLI とかで直ぐに切り替えられるのでコスパが良い削減策です。
NewsPicks でもコンテナインサイト必要ない環境で有効になっていることがありましたので無効化したらそこそこコスト削減できました。
何でも Fargate を選択すれば良いわけではない
Fargate を利用すれば管理の手間は減るのですが、コンピューティングコストが下がるという訳ではないようです。
詳細については以下安藤さんの記事をご覧頂きたいのですが、Fargate採用による運用コスト軽減とコンピューティングコスト増加を天秤にかけてみたら後者のデメリットが大きく、NewsPicks では ECS on EC2 も利用しています。
当然ですが使用するインスタンスタイプによって条件は変わってきますので一概には言えませんが「とりあえず何でもFargate!」というのは避けた方が良さそうです。
Fargate スポットを活用しよう
ECS on Fargate についてはスポットインスタンスが利用できますが、キャパシティプロバイダを設定することで通常のFargateインスタンスとスポットインスタンスが共存できます。 つまり本番環境においても一部は通常インスタンスにしておくけど他はスポットを利用する、という使い方が可能です。
もちろんスポットインスタンスが落ちた時のパフォーマンス面については十分考慮する必要があります。 なのでまずは非クリティカルな場所からスポットインスタンスを導入していくのが正攻法かなとは思います。
NewsPicks での取り組み内容は以下の西さんの記事ご参照ください。
Lambda
Graviton対応しよう
x86よりArmを使う方が約2割安くなるのでどんどん置き換えていっています。
Lambda以外にも RDS, ElastiCache については、旧世代タイプからすべてGraviton(r6g)に変更しコストをかなり下げることができました。
ECR
イメージサイズを抑えよう
ECR料金はストレージ料金とデータ転送料金がかかりますが、大体は前者の方が多くかかると思うのでイメージサイズを減らすのが有効です。
施策としては可能な限り distoless とか slim とかのベースイメージを使い、不要なファイルやライブラリはコンテナに含めない様に進めております。
詳しくはDocker公式に Dockerfile のベストプラクティスがありますのでご参照ください。
ライフサイクルポリシーを設定しよう
手動でECRリポジトリ設定している際はライフサイクル設定忘れに要注意です。
経過日数、最大イメージ数、タグフィルタなど細かく条件指定できるので使わないイメージは削除していきましょう。
ネットワーキング
VPC
VPCエンドポイント入れ忘れに注意
S3とかDynamoDBを使う際にVPCエンドポイントを積極的に利用しましょう。 これが無いと通信する際に NatGateway を通ったりして余計な料金がかかります。
ちなみにVPCエンドポイントにはInterfaceタイプとGatewayタイプの2種類があり、前者の場合は存在するだけでお金がかかります。 後者は通信料金だけですがS3とDynamoDB用にしか利用できないので注意しましょう。
VPCエンドポイントのつけ忘れに気づくために、NAT Gatewayの転送料金の内訳を知るための分析方法はこちら
VPC Flow Logs のS3バケット設定に注意しよう
VPCフローログについて、S3バケットに送信している際はライフサイクルルール適用するのを忘れていませんか?
手動で作る場合はバケットARNしか指定しないので割と落とし穴です。
NewsPicksでもSREチームでコスト調査したときに気づきライフサイクル設定入れました。
ストレージ系
RDS
スロークエリ出てないかAPMを使って確認
RDSログやAPMの機能使ってスロークエリ出てないか監視しておきましょう。
NewsPicks ではAPMとして NewRelic 活用しており、トランザクション処理にかかる時間をグラフ表示できる機能があります。 加えて、デプロイメントマーカを打つことで、どのリリースでトランザクション時間が伸びたというのが一目瞭然で分かります。お使いのAPMでも類似した機能があれば積極的に利用していきましょう。
DynamoDB
バーストキャパシティを理解しよう
DynamoDBでもバーストという概念があります。 キャパシティモードがプロビジョニングで、瞬間的にスループットが跳ね上がるケースの場合はこれで対応できるケースがあるので判断基準として使っています。
ただし最大5分間という制約と、将来的にここの仕様変更されるかもねと書いてあるので過信は禁物です。 詳細は以下の公式ドキュメントをご確認ください。
キャパシティモードを適切に設定しよう
キャパシティモードの2つの選択肢、オンデマンド、プロビジョニング(オートスケール有無)について、NewsPicksではどう使い分けているかです。
- オンデマンド
- 普段はほぼ使わない、若しくは偶にスパイクが起こる様なテーブルだとオンデマンドでOKです。
- キャパシティモード(オートスケール無)
- 負荷が一定若しくは予測できるケース。万が一キャパシティ超過してもユーザ影響が少ないテーブル用。
- キャパシティモード(オートスケール有)
- 負荷に波があり、予測もしにくいテーブルに適しています。
S3
バージョニング機能は正しく使い分けよう
これで結構痛い目にあいました。 ユースケースにより有効/無効決めて頂ければ良いのですが、無効にしておくべきだったのに有効になっていた場合はストレージ料金に注意してください。
想定通りにバージョニング無効、ライフサイクルルールで「何日間で有効期限切れ」という設定を入れておけば自動的にオブジェクト削除されます。
ただバージョニング有効になっている場合は削除マーカが打たれるだけでデータ量としては削減されませんので皆様もご注意ください。
何でもGlacierに突っ込めば良いという訳ではない
とりあえずで古くて使わないデータがいっぱいあるからGlacierに置いておこうというのは危険です。
ライフサイクル移行料金というものがあり、例えば Glacier Deep Archive に移行する場合は1000リクエストあたり0.065ドルかかります。
例として1000万のオブジェクトを移行しようとすると650ドルもかかってしまいます。オブジェクト数は多いけどデータ量としては多くない場合、変にGlacierに入れておくよりは標準ストレージのまま残しておく方が安い場合もあります。
私はオブジェクト数の確認怠ったまま作業してしまい、ライフサイクル移行料金を爆増させてしまいました。
その他
CodeBuild
コンピューティングタイプを見直そう
CodeBuild はコンピューティングリソースを選択できるのですが、コスト削減しようと思うあまり必要以上に小さいタイプ選択していないでしょうか。 開発人数とビルド時間によってはリソース増強した方が工数的にはお得な場合もあります。
SREチームにもビルド高速化できないかとの要望があり、リソースを上げても工数的には十分元が取れると判断し増強した経緯があります。
CloudWatch
ログ保持期間設定しよう
Lambdaとか作った際にやりがちですが、いつの間にかロググループの保存量が跳ね上がっていることがあったので偶にはチェックしましょう!
ログ出力内容を見直そう。
私の経験ですが、気軽に入れて本番リリース時に消し忘れた console.log() が思わぬコスト増につながっていることが過去にありましたのでコードレビュー時は気をつけましょう。
あとは定常的に出ている warning 系ログも何とかして対応しましょう。 コスト削減はもとより、障害発生時のログ調査するときにこういうログがあると結構な認知負荷がかかります。
不要な CloudWatch Alarm を消し去る
アクションが設定されていない、監視先リソースが既に無い、通知先が設定されていないとかの不要なアラームを洗い出して消しましょう。 メトリクスアラームは1つあたり月0.1ドルと大きくは無いのですが、膨大にある場合は効果ありです。
NewsPicks では飯野さんがアラーム精査と削り込みをしてくれました、下記ブログもご参照ください。
CloudTrail
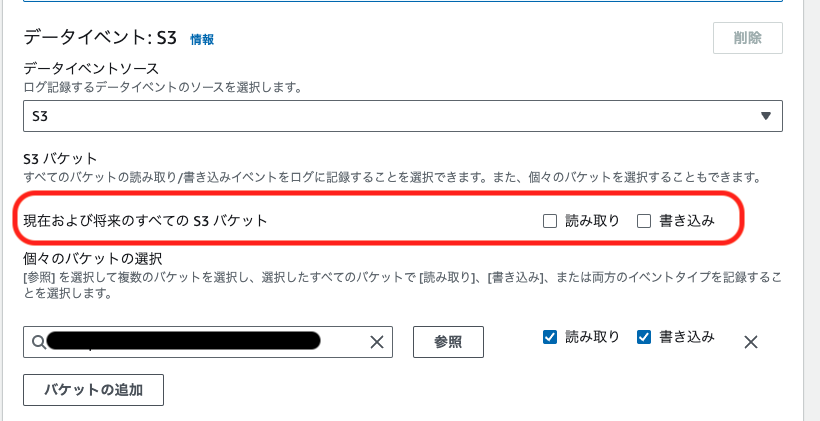
S3データイベント記録は最小限に絞ろう
CloudTrail で証跡を残すときにデータイベントを選択できますが 現在および将来のすべての S3 バケット についての項目は注意しましょう。
これが有効になっていると今後作成される全てのS3バケットについて、記録が保存されてしまいその分課金されてしまいます。
監査用として残すべきログについて確認し、必要なものだけ残す様にしましょう。DynamoDBがイベントソースの時も同様の設定あるようなのでご注意ください。
告知
NewsPicks ではエンジニアを募集中です!ご興味のある方はこちらまで。