こんにちは。ソーシャル経済メディア NewsPicksのSREチームで仕事をしている安藤です。
NewsPicks Advent Calendar 2023 の1日目ということで、日常の業務風景から軽いコスト最適化TIPSをご紹介します。
AWSコストを最適化したいよぉ〜
NewsPicksはおかげさまでサービス10周年を迎え、ユーザー数も事業も伸びておりますが、 事業の成長やエンジニア組織の拡大に比例してAWSコストが増え、円安でさらに日本円での負担が増え、となると事業の利益率にも少なからず影響がでます。
私が所属するSREチームでは、「売上に対するAWSコストの割合は、規模が拡大するほど減っていくべき」という考えを持っており、 積極的にAWSサービスの使い方を見直して毎年コストを削っていくつもりで仕事をしています。
AWSが提唱するCloud Financial Management Frameworkによると、Financial Operations (FinOps)の実践には4つの柱がありますが
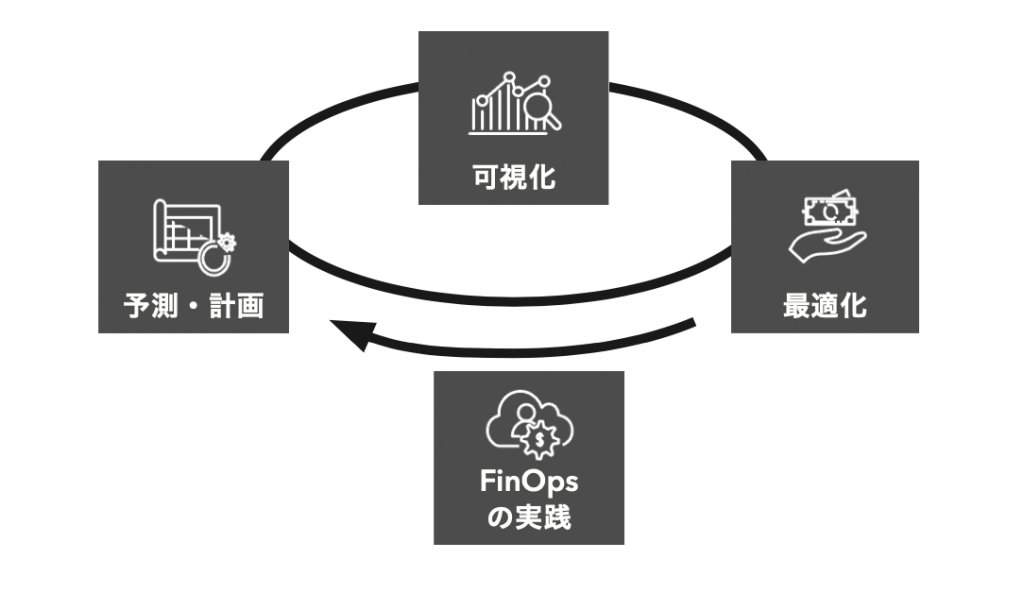
クラウド利用費用を最適化するための最初のステップとして、利用しているリソースがどの組織 / チーム / 開発プロジェクト / サービスに帰属しているのかを明確にし、利用費用・利用量を監視・管理することが必要です。
というわけで、毎日の日課はコスト異常検出(Cost Anomaly Detection) と Cost Explorerをひたすら見ていくことになります。
私は親の顔よりCost Explorerを見ています。
ある日のコスト異常検出:Elastic Block Storeの料金が増えた!? → 嘘でした
毎朝のチーム朝会でSlackチャンネルをチェックしているので、コスト異常検出の通知に気づきます。
少し見づらいですが、メール本文内の View In Anomaly Detection のリンクをクリックすると、Slackからそのままコスト異常検出の詳細画面に飛べます。
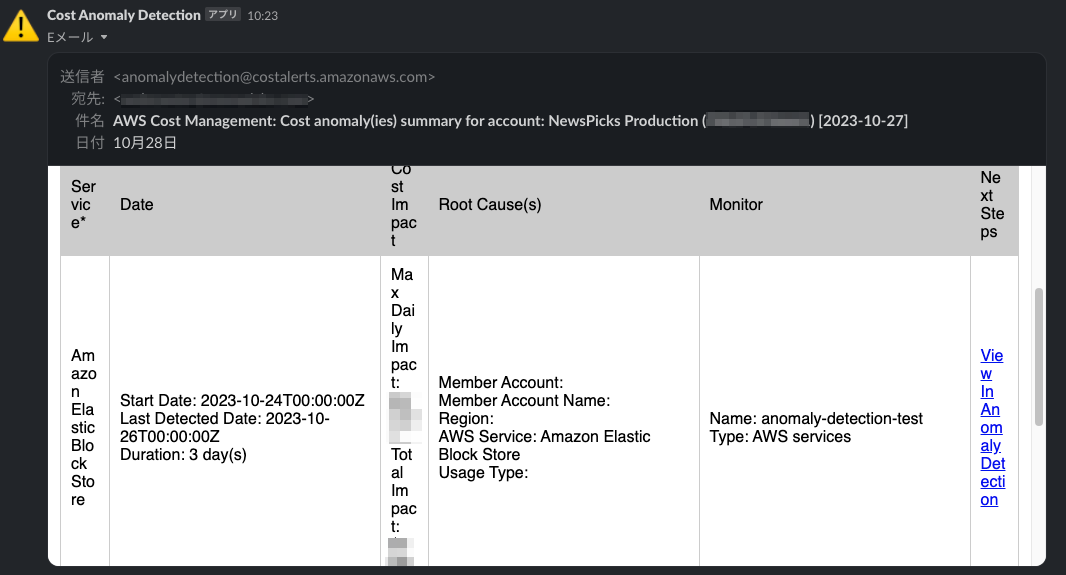
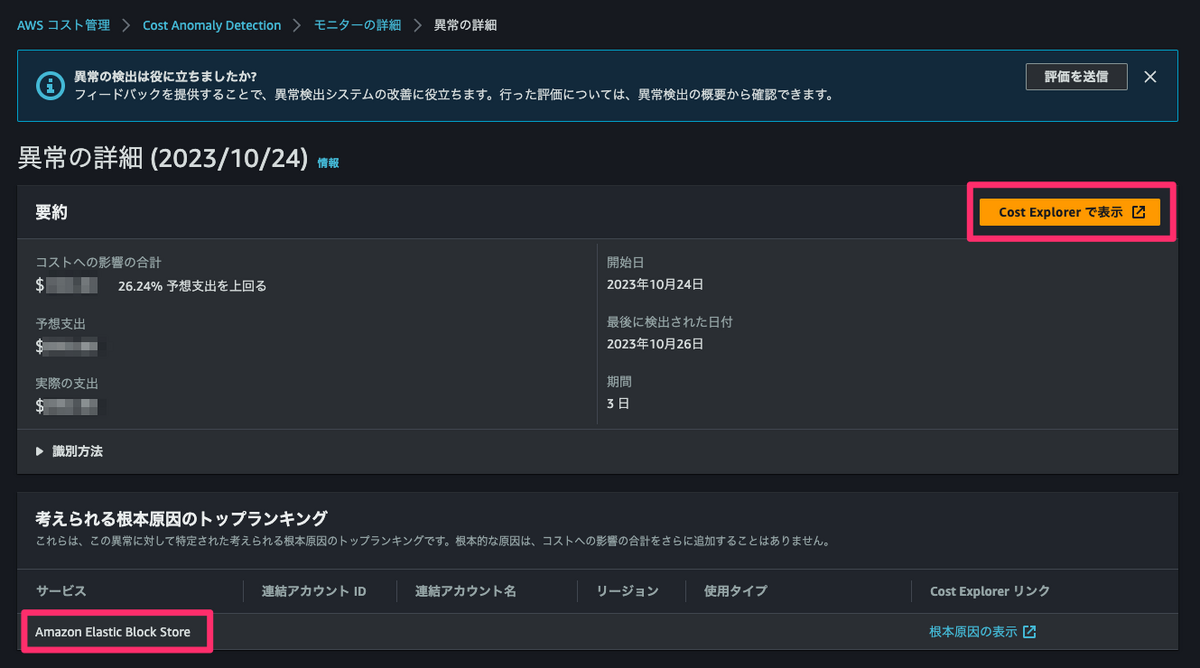
コスト異常検出はAWSサービス単位で検出され、「Elastic Block Store」と表示されています。
ここで「なるほど、EBSの料金が増えたんだな」と騙されてはいけません。
Cost Explorerに遷移すると、サービスが「EC2 その他」でフィルタされています。
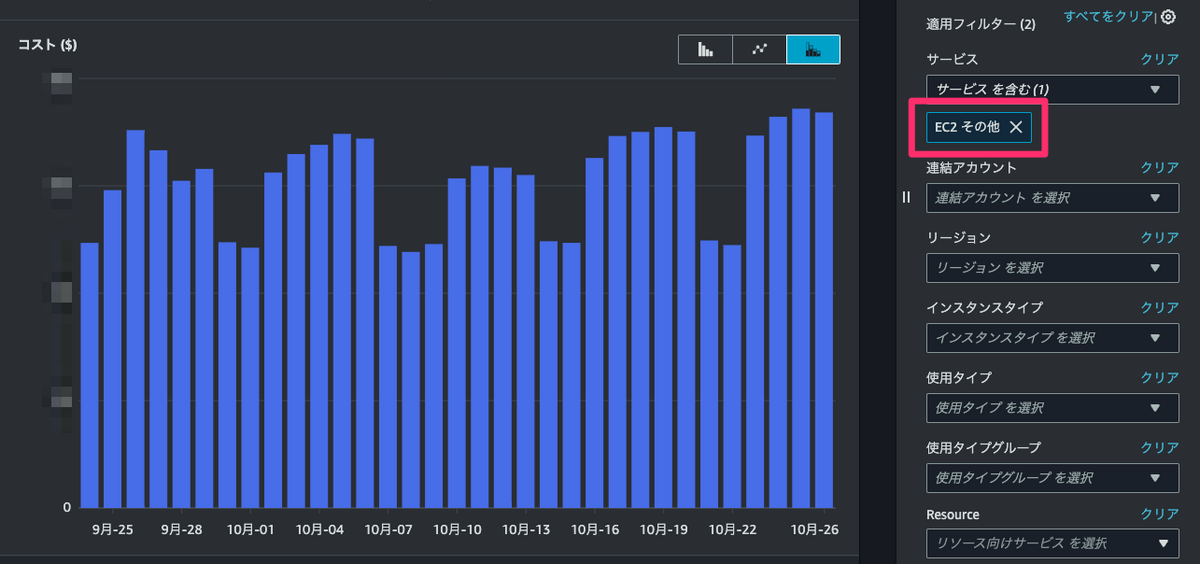
AWSの請求明細に詳しい方はご存知かと思いますが、AWSのサービス分類 「EC2 その他」にはEBS料金、NAT Gateway料金、データ転送料金、ElasticIPの料金などが入ってきます。
どうやらコスト異常検出には、サービス分類 「EC2 その他」の異常検出が「Elastic Block Store」と表示される不具合があるようです。それだけEBSが原因であることが多いのかもしれませんね。
コスト異常検出からCost Explorerに遷移したら、様々なグループ化を試して、フィルターをかけてコスト上昇原因を絞り込んで特定していくのが定石です。
今回は以下を試して絞り込みました。
- 連結アカウントでグループ化する。→「本番アカウントが増えてるね」→ 連結アカウントを本番アカウントでフィルターする
- 使用タイプでグループ化する。→「
APN1-NatGateway-Bytes (GB)の上昇率が高いように見える」→ 使用タイプをAPN1-NatGateway-Bytes (GB)でフィルターする
結果、コスト異常検出の詳細から遷移した時点のCost Explorerよりも、かなり顕著にコストが上昇したことがわかるグラフになりました。
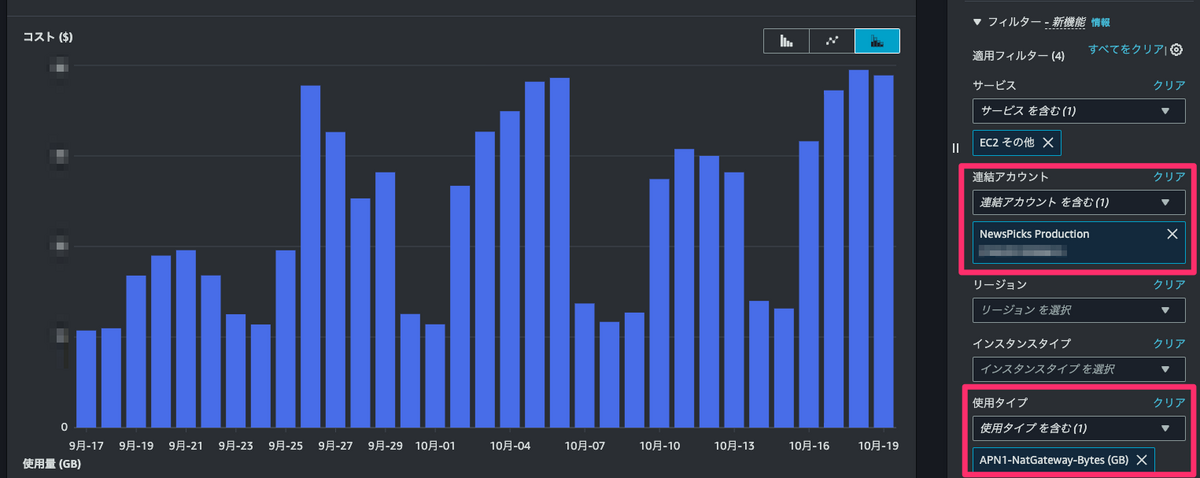
コストが増え始めた時期や、休日はそこまで増えていないが平日は大きく増えている、ということまでわかります。
慣れれば、コスト異常検出の通知からここまで2〜3分で瞬殺できる日常の事務仕事になります。
閑話休題:Cost Explorerの機能強化
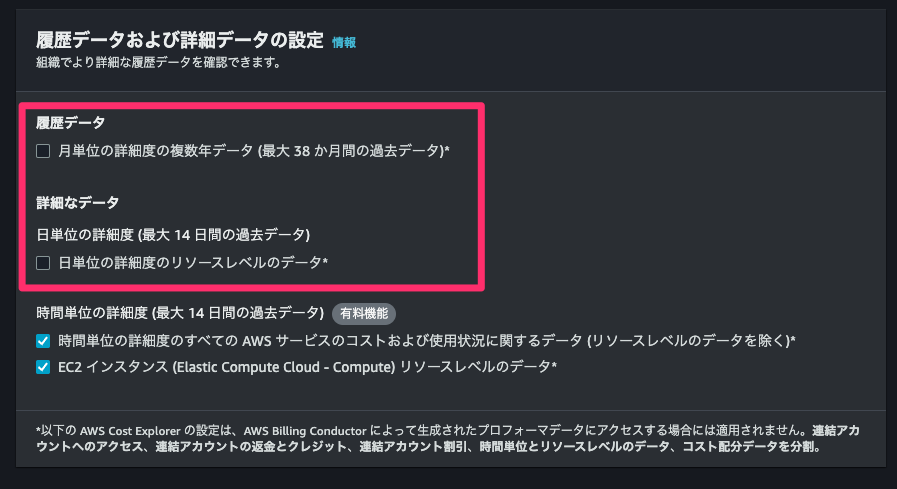
Nat Gatewayのデータ転送料金が増えたことがわかりましたが、通常Cost Explorerではこの先の調査は難しいと思います。 ところが、先日 2023/11/16 に『AWS Cost Explorer がより詳細な履歴データの提供を開始』というアップデートがありました。
これまではCost Explorerではリソースレベル、今回の場合「どのNAT Gatewayのデータ転送料金が増えているのか」を絞り込んで特定することはできませんでした。
上記のアップデートにより、『AWS の任意のサービスについて 14 日間のリソースレベルデータを日単位で有効にすること』ができるようになったので、直近2週間のデータであれば、事前に対象のサービスのリソースレベルデータを有効にしておくことで、Cost Explorerでリソースの特定ができるようになります。
全体に占める割合が大きかったりコストが変動しやすいサービスについては設定を有効にしておくことをおすすめします。なんと無料だそうです。
ただ、NewsPicksの環境では、AWSアカウントごとのVPCとNAT Gatewayを集約することで管理負荷を低減しコスト効率を高めているため、 「本番環境のNAT Gatewayっていったらアレだよね」と自明です。
そのためCost Explorerでリソースを特定できても今回の調査ではそれほど役立つことはないですが、VPCとNAT Gatewayが用途ごとに細かく分離されている環境であったり、S3バケットやデータベースサービスなどのコスト上昇の際はリソースレベルのデータがあるとCost Explorerでコスト上昇原因の特定が進められて助かることもあると思います。
個人的には、38ヶ月までの長期間のコストの経年変化をCost Explorerで確認できるようになったことが感動です。
今までもQuickSightで見ていましたが、やはりCost Explorerは手軽で使いやすいので
これまでは1年より前との比較やリソースレベルのコストを見る時は、一旦Cost Explorerを離れてCost and Usage Reports(CUR)のCSVをS3に出力してAthena + QuickSightで分析するのがプロのFinOpsエンジニア(?)の仕事でしたね
— あんどぅ (@integrated1453) 2023年11月27日
今後はCost Explorerを離れなくてもUIぽちぽちで分析できる仕事が増えそう https://t.co/RW7gS410Kc
本題:VPC Flow LogsをAthena + QuickSightで 分析してデータ転送料金の内訳を調査する
ここからタイトルを回収していきます。
ここまではコスト異常検出を起点にCost Explorerをぽちぽちしていくだけなので単なる事務仕事ですが、プロ(?)の仕事はここからかと思います。
まずはよく見かける感じのこちらの図をご覧ください。
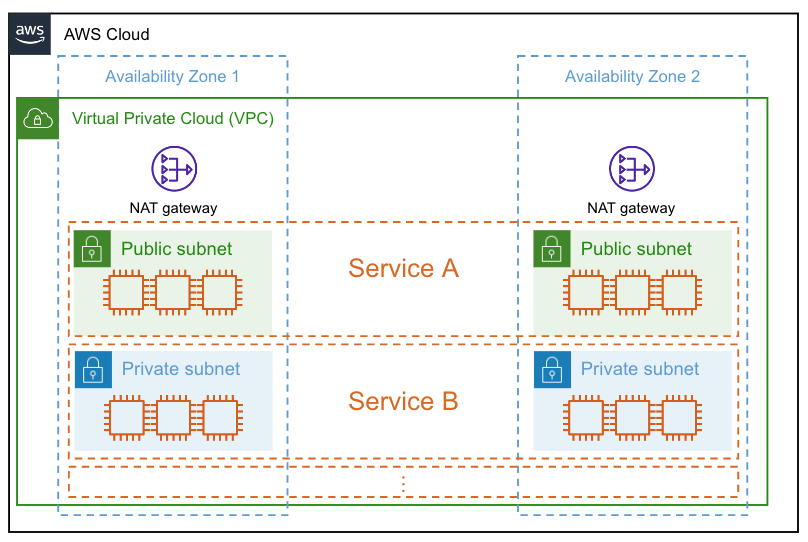
このようにVPC内に複数のサービスが存在する場合(NewsPicksでは10以上です)、どのサービスがNAT Gatewayのデータ転送量を多く使用しているかを調べることで、NAT Gatewayの料金上昇の原因が特定できる可能性があります。
VPC Flow LogsはVPC内のトラフィックのログ記録です。NewsPicksでは有事の際のためにS3バケットに保存していました。
今回は、NAT Gatewayのデータ転送料金上昇の原因を特定するため、NAT GatewayのIPアドレスに対して送受信しているトラフィックを集計することにしました。
S3バケットに対してAthenaテーブルを作成する
ここに技巧を凝らすポイントはありません。
ドキュメントを参考に好きなテーブル名で、保存先のS3バケットとprefixを指定して、Athenaテーブルを作成してください。
QuickSightにデータセットを作成し、Athenaテーブルを分析できるようにする。
AWS Configコスト上昇の原因を調査:QuickSight + Athenaの分析ツールを活用 で同じSREチームの美濃部さんがConfigの記録データに対して似たようなことを説明してくれました。そちらもご参考ください。違いはデータ形式くらいです。
2年前に当時CTOの高山さんが AWSのコストモニタリングの知見をシェアしたい の中で Cost & Usage Report (CUR)をQuickSightからAthena経由で分析することを勧めていますが、この文化が脈々と受け継がれて我々のチームはこんなことばかりしています・・・笑
一点だけVPC Flow Logs固有の工夫があるとしたら、パーティション化された日付範囲でデータ量を絞ることです。
複数のサービスを集約しているNewsPicksの本番VPC Flow Logsはログのデータ量もかなり大きかったため、QuickSightで軽快な分析を行うには全量を対象にするわけにはいきませんでした。
分析から示唆を得るために十分な期間はどれくらいかを睨みつつ、許容できるレスポンスを試しながら、4週間程度であれば十分な期間で快適に操作すると判断し、VPC Flow LogsのAthenaテーブルに対して以下のクエリでデータセットを作成しました。
select * from "vpc_flow_logs" where date > current_date - interval '28' day
分析の要件が明確なら SELECT * ではなく必要な項目に絞って取り込みデータ量を減らすことで、パフォーマンスを改善したり更に多くの期間を取り込むのも良いと思います。
分析をしていると見えている項目を使って色々確認したくなるもので、最初は全項目取り込んで試行錯誤しようと判断しました。
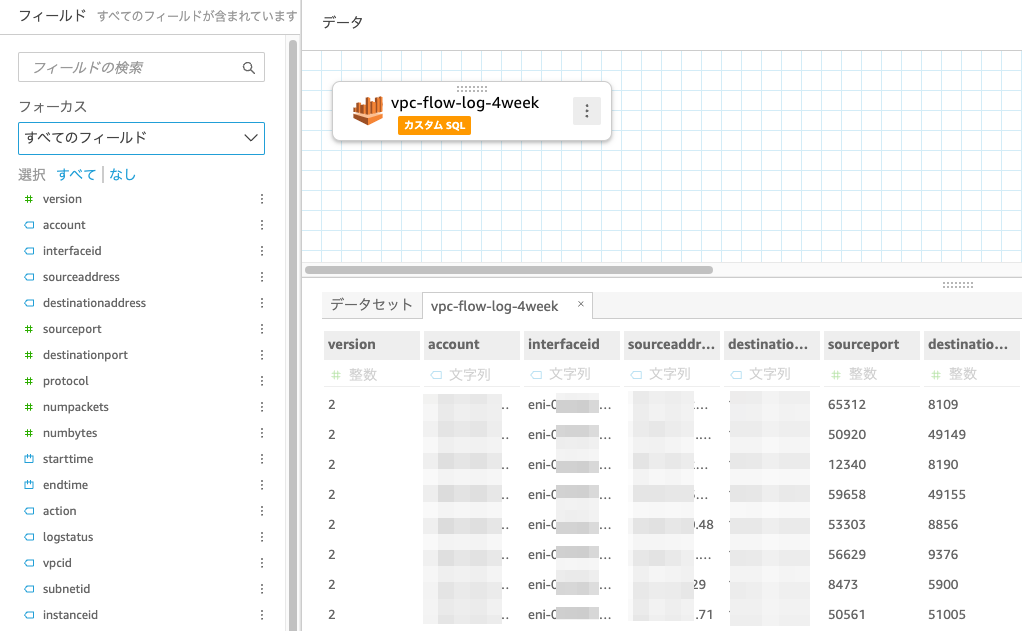
QuickSightに計算フィールドを作成し、IPアドレスのセグメントを集計できるようにする
QuickSightの計算フィールドを使いこなしている方はあまりいない気がしたので今回のブログを書くモチベーションになりました。これすごく便利です。
今回の目的は『NAT GatewayのIPアドレスに対して送受信しているトラフィックを集計して、データ転送量が増えたサービスを特定する』でした。
VPC Flow Logsには sourceaddress と destinationaddress という項目があり、送信元/宛先IPアドレスが記録されているのでこのIPアドレスごとにデータ転送量を集計すれば良いと思えます。
QuickSightの前に、試しにAthenaでNAT Gatewayに対してデータ転送量が上位のIPアドレスを特定するために以下のようなクエリを書いたところ、
select sourceaddress, sum(numbytes) as sumbytes FROM "vpc_flow_logs" where day = 'とある1日' and destinationaddress = 'NAT Gatewayのprimary IPアドレス' group by sourceaddress order by sumbytes desc
とある1日だけでIPアドレスの数が数千件、データ転送量が上位のIPアドレスを見てもばらばらで示唆を得ることができませんでした。
NewsPicksの本番環境では、VPC内のサービスごとに/24でサブネットをマルチAZで割り当てているため、IPアドレスの第3オクテットまでがわかればサービスを特定できます。
AthenaとQuickSightの行き来に慣れていれば、 「さて、AthenaのクエリでSPLIT_PART関数を使って第4オクテットを置換してデータセットにネットワークセグメントの項目を追加するか。一旦QuickSightの分析を抜けてデータセットを更新した後また戻ってくるの面倒だなぁ」くらいに思うところでしょうか。
実はそれ、QuickSightでもできるんです。
分析ページから演算子や関数を利用して目的に合ったフィールドを作ることができます。
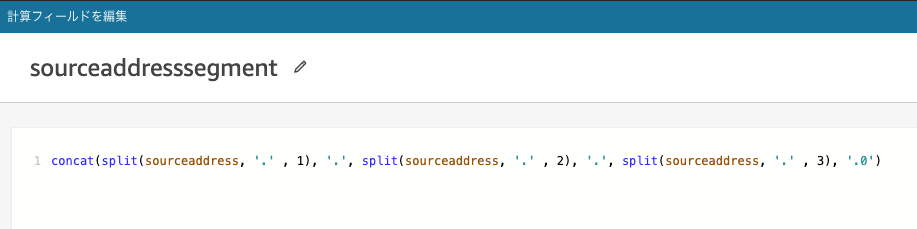
送信元IPアドレス(sourceaddress) 192.168.0.123 を 192.168.0.0 に変換する計算フィールド(sourceaddresssegment) が以下です。
concat(split(sourceaddress, '.' , 1), '.', split(sourceaddress, '.' , 2), '.', split(sourceaddress, '.' , 3), '.0')
計算フィールドは、QuickSightの通常のフィールドと同じようにビジュアルの軸・値・グループ化に設定して可視化ができます。
そうして出来上がったグラフがこちらです。
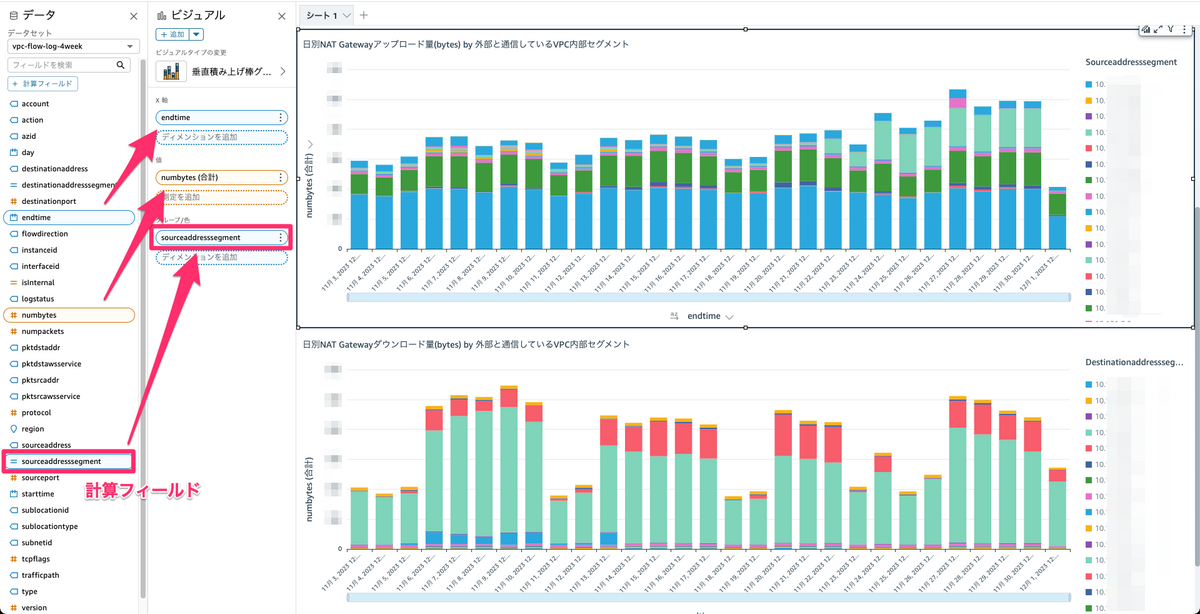
sourceaddressがNAT Gatewayの時はアップロード、destinationaddressがNAT Gatewayの時はダウンロードと判断できるので、アップロードとダウンロードでグラフを分けて、日別のデータ転送量の棒グラフをVPC内部セグメント(=サブネット)で色分けしました。
この分析により、データ転送量が支配的なセグメントがわかりどのサービスでデータ転送量が増えたのかが特定できました。
コスト異常検出の直接原因だけでなく、この可視化により気づいたコスト最適化施策もいくつかあり、全て実行することで年間3桁万円以上のコスト削減・利益創出の機会を得ました。
対策の例としては以下です。減らしがいがあり、まさに宝の山でした。
- 単純にVPC Endpointを作成していなかったサービスに対してVPC Endpointを紐付けてNAT Gatewayを経由しない
- CIの中で何度もインターネットにアセットを取りに行く処理があったため、ECRのプルスルーキャッシュやCode Artifactなど内部にキャッシュを持ちインターネットアクセスを減らす
- Webリクエスト起因のアウトバウンド通信の回数・転送量が多かったので、そもそもリクエスト数を減らすためのCDNの活用を検討する
終わりに
NAT Gatewayのコスト上昇をきっかけに、とりあえず何かあった時の調査用に保存しているだけだったVPC Flow Logsを本格的に活用し分析できるようにしました。
NewsPicksはソーシャル経済メディアという事業の特性上、ニュース記事の画像や経済番組の動画など、コンテンツ量相応のデータ転送料金がかかっていました。
全体のコストの中でかなりの割合を占めているものの、サービス提供の必要経費と諦めて長らく見直しできていなかったのですが、VPC Flow Logsを見ていくことで、「このサービスに対してこのデータ転送量は無駄が多いのではないか?」など気づくことができ、今後のコスト最適化に役立てられそうです。
QuickSightはAthenaを直接クエリするよりも素早く試行錯誤できる集計や可視化の機能を提供しています。
ぜひみなさまのコスト最適化にもお役立てください!