この記事は NewsPicks Advent Calendar 2024 の8日目の記事です(が、公開はずっと遅くになってしまいました!)。
ソーシャル経済メディア「NewsPicks」の武藤です。
サービスを安定的に運用するには、アプリケーションの動作状況を把握することが必要不可欠です。これには、定量的な測定(応答速度やメモリ・CPU使用量などの数値的なパフォーマンス指標)と定性的な測定(個別具体の処理の入力や出力など)の両方が必要です。
NewsPicksではNewRelicを活用して定量的な測定を行っています。アドベントカレンダーの7日のブログ記事でもNewRelicを扱っていますのでご覧ください。
一方で、定性的な観測を迅速に行う仕組みも同じくらい重要です。しかし、Athena や Redshift を使用すると、規模感や手間の面で大げさすぎる場合があります。そんなときに CloudWatch Logs Insights(以下Logs Insights表記)がちょうど良い解決になることがあります。
宣伝ですが、12/18発売のSoftware Design 2025年1月号に私の記事が載っていますので、是非購入してください!ソフトウェアアーキテクチャと事業の発展の関連について書きました。 https://gihyo.jp/magazine/SD/archive/2025/202501
実際のトラブル対応の例
システムを運用していると「うまく動いてないみたいなんですが調べてもらえますか?」という調査依頼の対応がよくあります。例えばNewsPicksでは取り込んだはずの外部記事が出てこないとか、タイムラインが更新されていないなどという状況が該当します。
先日私が実行したクエリを紹介します。RSS取り込みの結果、特定の記事がどのように処理されたかの問い合わせに答えるためのクエリです。
fields @timestamp, @message
| filter strcontains(@message, "{記事ID}")
ごく簡単なクエリですが、何をやっているかは読めばわかると思います。記事IDのログを取りだしているだけです。これを該当のロググループに対して実行するだけで、処理の状況を確認することが出来ます。Logs Insightsは高速に結果が返ってくるため、すぐに状況を事業部のメンバーに共有し、問い合わせは解決しました。
もうすこし複雑なクエリでも、難しくありません。これはRSS取り込みを行おうとしたがRSSが404になってしまった回数を集計しています。
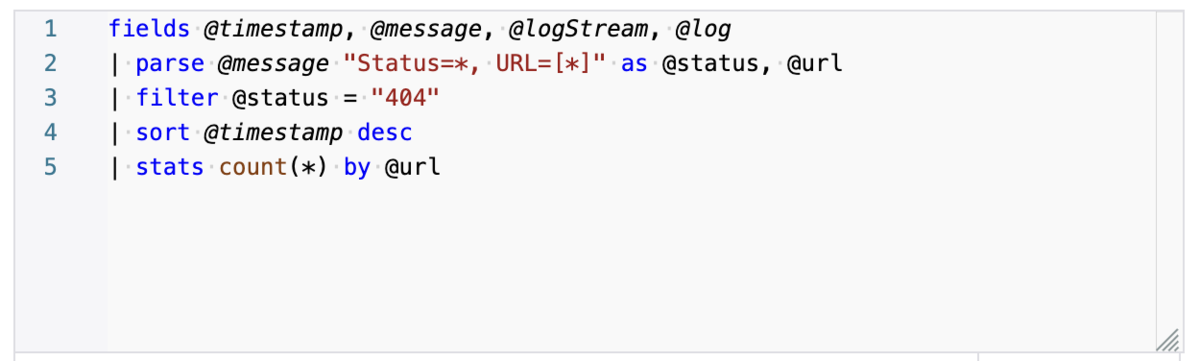
| parse @message "Status=*, URL=[*]" as @status, @url の部分では、@message の文字列中から Status=404, URL=https://... のような文字列を取り出し、404 の部分を @status、https://... の部分を @url で参照できるようにしています。複雑な正規表現やパーサーを作らなくても簡単にログをパースできていることが伝わるでしょうか。
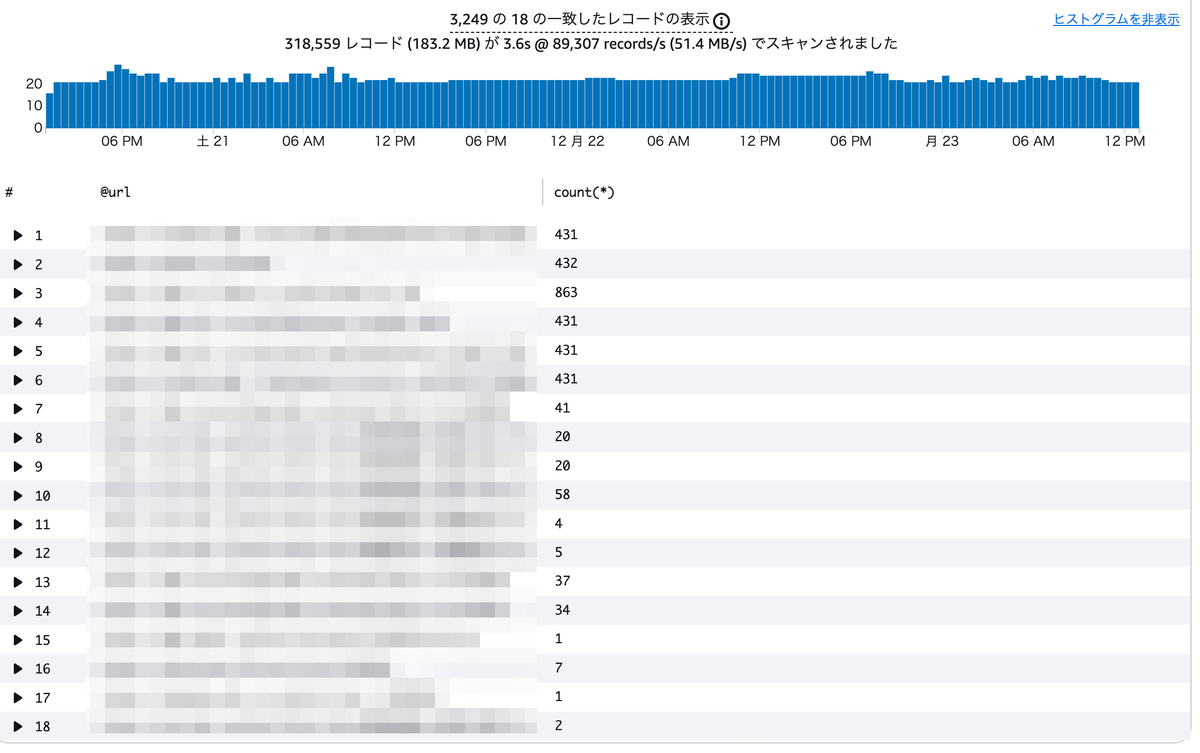
結果はこのように表示されます。ヒストグラムや詳細が自動で出るため、難しいことを考えなくても良いようになっています。
ログ運用のコツ
このようにLogs Insightsを活用して障害対応の時間を短く済ませるには、難しいことではありませんがいくつか準備が必要です。NewsPicksではどんなことを意識して運用しているかをご紹介します。
- 構造化ログを送る
- ログを出す
- プロセス別にロググループを分ける
- web系のログは、直接S3に置く
ログ永続化の全体像
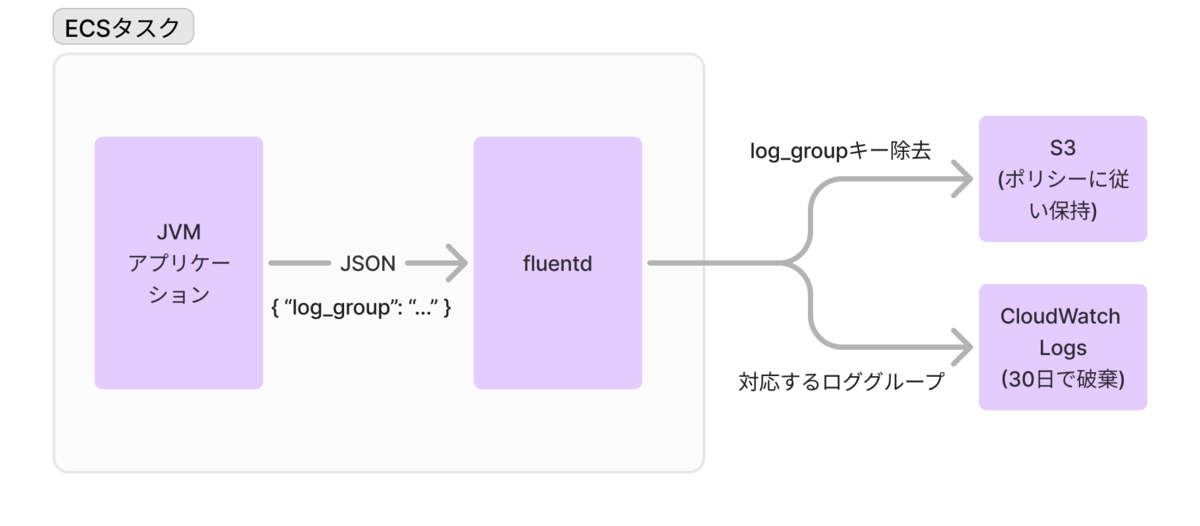
個別の内容の前に全体像をお見せします。NewsPicksでは基本的にはアプリケーションはECSタスクとして動いています。その中でサイドカーとしてfluentdが動いていて、アプリケーションが出したJSONログをS3とCloudWatch Logsに分配しています。
CloudWatch Logsは直近のログを素早く確認するための用途として割り切っているため、CloudWatch LogsからS3への永続化は行わず一定期間で破棄しています。その代わりにfluentdから直接S3に保存しています。
構造化ログを送る
運用上最も大事な設定です。アプリケーションから出すログをJSON形式にして、複数行のログでもCloudWatch Logs上で一つのログとしてまとまるようにします。こうしておかないと、ログの検索結果の前後を辿らないと必要な情報にたどり着けないという手間が発生してしまいます。たとえばスタックトレースが一行一行ぶつ切れてしまうと非常に追いにくいです。後から確認したい全ての情報を一つのメッセージとして出力し、それを最後まで保つことが運用を楽にします。
ログを出す
これも非常に大切です。ログが出ていないと調査しようがありません。特に、「何が」「どうなっていたから」「何をした」の情報を出すのが大事です。「何が」のところでは処理のキーになるもの(記事に関する処理であれば記事ID、RSSの処理であればRSSのURLなど)を必ずログに出しておくことも意識しておく必要があります。
JSONとしてログが出ていれば、フォーマットについては細かいことを考えなくても大丈夫でしょう。ただし、TSVなどでログを出す場合は、どのログもキーの順番が同じになるようにする必要があります。キーの順番が変わってしまうと簡単なパターンでログを解析することが出来なくなってしまいます。例外をキャッチしてログを出す場合、例外のメッセージの中に必ずキーが入るように工夫してください。何らかのコンテキストとして今の処理対象を持ち回すと良いでしょう。
バッチ・ワーカーごとにロググループを分ける
ロググループを用途ごとに分けています。Logs Insightsでログを見る際に別の処理が混ざらずに便利です。 ロググループを分けるのはバッチ・ワーカーをデプロイするインフラ側で半自動的に行われるため、開発者が普段意識する必要がないようにしています。
具体的には、ECSタスクに環境変数としてプロセス名を渡しておき、アプリケーションのlogback.xmlでJSONにする際にlog_groupプロパティを追加しています。fluentd側ではこのキーを参照してCloudWatch Logsにログを送ります。
web系のログは、直接S3に置く
本記事の主題であるLogs Insightsの活用はできないのですが、NewsPicksでの運用方法として紹介します。GZ圧縮された状態で5GiB/day程度ありログの転送料金が割高となるためCloudWatch Logsを使わずに直接S3に送っています。このログの解析が必要になる際にはAthenaやRedshiftを活用します。
問い合わせ対応はバックオフィス業務が中心であり、バッチ・ワーカーのログやDBの内容をみて解決していくためLogs Insightsが活躍します。web系のログは一般ユーザー向けサービスのシステムログであり、ユーザーからの問い合わせはシステムログではなくユーザーの行動ログをみることになるため、問い合わせ対応の中でアクセスすることはまれなため、費用削減のためにS3にだけ置くことにしても問題ありません。
Logs Insights を覚えて帰ってください。
本記事ではNewsPicksでのLogs Insightsの利用方法をご紹介しました。ログの定性的な測定は定量的な測定に比べて一般的な解が少なく、知っていれば劇的に時間が短縮できるのに知らないが故に時間がかかってしまうという状況が多くあるように思います。AWSユーザーにとってはかなり使えるツールです。本記事がその状況を少しでも減らせられれば幸いです。