はじめに
ソーシャル経済メディア「NewsPicks」SREチーム・新卒エンジニアの樋渡です。このブログは、NewsPicksの NewsPicks Advent Calendar 2024の24日目の記事となります。
今回は、AWSサービスである「OpenSearch」「ECS」とデータウェアハウスである「Snowflake」を用いて、弊社で使用している開発環境にコスパよく効率的な検索インフラ基盤を構築し、NewsPicksの重要な機能の一つである検索機能の開発者体験を向上させたお話です。このブログではインフラ構成の見直しによるコストコンシャスな検索環境整備とSnowflakeの機能である「Zero-Copy-Clone」を使ってindex作成処理の課題を解決した実践的な活用法のお話をしていきます!!
お話の内容
弊社の開発環境(以降dev環境)は15環境ありますが、これまで一つの環境(以降dev-12)でしか検索機能が動作しない状態でした。検索ページの動作確認はdev-12でしか確認できない状態であり、このような状態では、検索ページの機能開発が不便でありスピード感のある開発ができないことでユーザーへの価値提供が遅れかねません。今回のお話は、既存の検索基盤構成が抱えていた問題を解決し、全てのdev環境にコスパの良い検索基盤構成を構築することで検索ページの開発者体験やメンテナンス性を向上させたぜ!というお話となっております。
抱えていた課題
弊社の検索基盤は、主にECSとOpenSearch Serviceで構築されています。cdkで管理されており、インフラ構築自体は簡単にできる状態まで整備されていました。では、なぜこれまでdev環境に検索基盤が構築されていなかったのでしょうか?気になりますね。理由は大きく分けて、「コスト問題」、「index作成処理の問題」の2つでした。それぞれの課題点について詳しく深掘りしていきます。
コスト
まず一つ目の「コスト問題」についてです。既存のインフラ構成は次の画像のようなものです。
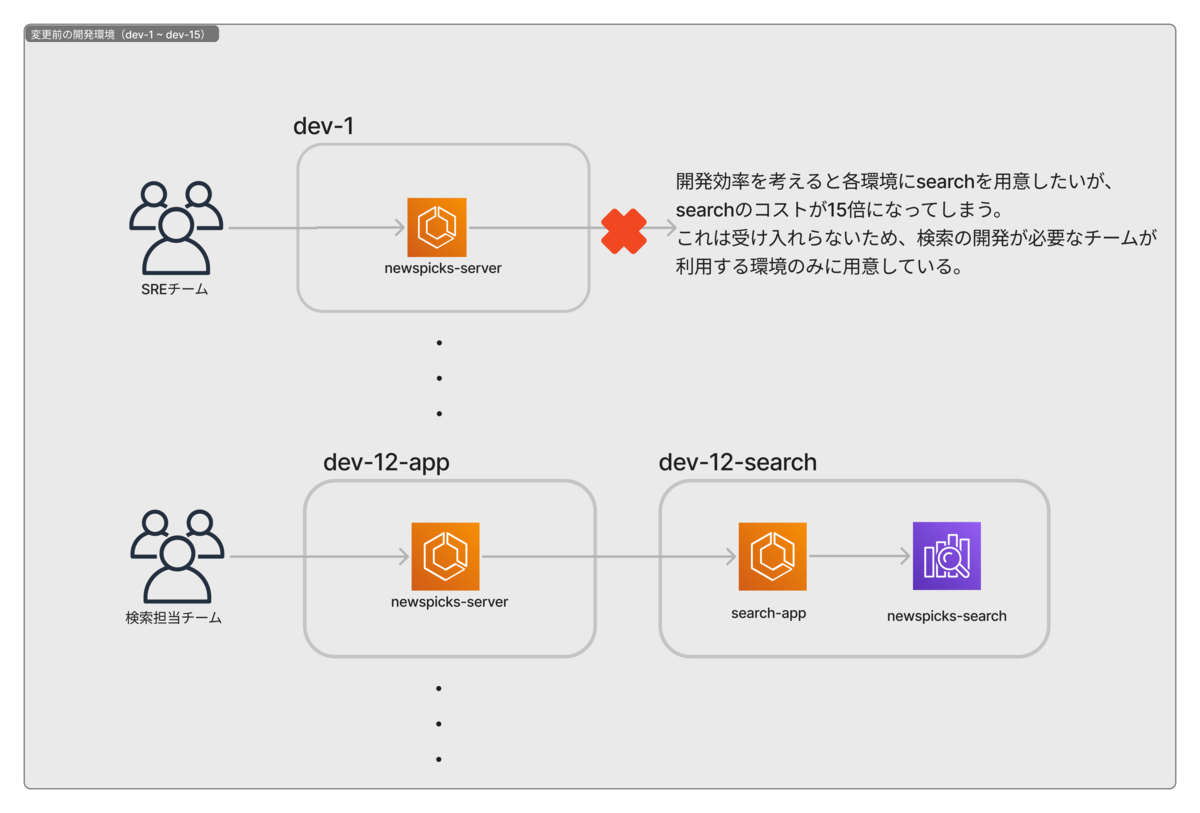
従来のインフラ構成は、一つのECSに対して一つのOpenSearchドメインが存在するという構成で、ごくシンプルなものでした。この構成には次のようなコスト的な問題点があります。それは仮にこのインフラ構成を全てのdev環境面にdeployした場合、一つの環境に対して独立したOpenSearchドメインが立ち上がることです。それが何でダメなの?って思うのではないでしょうか。説明します。
今回の検索基盤改善の目的は、「全てのdev環境で検索機能が使えること」だけです。環境ごとに検索indexの開発をしたい等の要望がない環境では、OpenSearchドメインを必ず用意する必要はなく要件に対して過剰なスペックのインフラを構築することになります。結果として、開発するわけでもないOpenSearchドメインを立ち上げることになり、余計なコストがかかってしまう状態となります。弊社では、積極的かつ継続的なコスト削減を行なっている中で、開発環境の15環境分のOpenSearchにかかるコストインパクトは絶大です。これまでコストと利便性を天秤にかけた結果、検索を担当するチームが普段使用する一つのdev環境のみに検索基盤を構築するという判断になっていました。今回、インフラ構成を工夫することでこの問題を解決していきます。
index作成処理の問題
次に2つ目の「index作成処理の問題」についてです。弊社のindex作成の仕組みは次の画像のような流れです。

基本的な処理は、digdagのワークフローとして実装されています。処理の流れとしては、RedshiftからS3へindex作成の対象となるデータを抜き出し、中間処理を挟んで別のS3へと入れ込んだ後、embulkを使用してOpenSearchへとinsertしていくという流れのものです。本番環境では参照するRedshiftに対してDynamoDBやRDSから毎日データを入れるワークフローが別に存在し、このワークフローの実行を待ってから検索index処理作成のワークフローが実行されるという流れを辿ります。ここで課題となったのは、「実行時間が長いこと」と「本番同等のindex作成はできない」ことです。この改善の設計に取り掛かった段階では、dev環境にあるDynamoDBとRDSからRedshiftへの同期を行い、検索indexを作成する処理までを開発者が手軽に実行できる手段を提供する予定でした。本番とは違うものの検索indexを作成すること(=検索ページを動かすこと)自体はできるため、実行時間の長さは妥協し採用となりました。index作成処理に対する開発者体験は悪いものの、検索ページを動かすことを優先する結果となりました。しかし、思わぬ要因でこの問題は解決されます。
課題の解決に行く前に課題点をまとめます。
- OpenSearchドメインが大量に立ち上がることによるコスト増加
- コストがネックとなり開発環境が用意できない、検索ページの開発体験・メンテナンス性の悪化に繋がり価値提供の機会損失を招きかねない
- 検索index作成処理の処理時間が長い
- 最新のデータ同期をしたい際、Redshiftへのデータ同期処理から動かす必要があり余計な時間がかかってしまう
どうやって解決していくか
では、課題点と解決の必要性がわかったので、どうやって解決していくのかについてです。今回あげた課題の中でまず解決しないといけないのはコスト問題です。これまでコストがネックとなり検索基盤の構築は一部のみにとどまっていました。なので、インフラ構成を見直し、コストの最適化を図ります。 今回、各開発環境での要件は以下の3つに分けることができ、それぞれに必要なリソースは以下のようになります。
- (A)検索機能を利用した開発がしたい = ECSもOpenSearchも環境独自のものは必要なし
- (B)検索サーバーの開発がしたい = 環境独自のECSが必要
- (C)検索サーバーと検索データの開発がしたい = 環境独自のECSとOpenSearchが必要
↑のような要件を満たすようにコストを最適化するにはどうすれば良いでしょうか?考え方は簡単です。必要な環境に必要なリソースだけを用意し、共通化できるものは共通化してしまえば良いです。具体的にいうと、最低限必要な共通で利用するOpenSearch(dev-newspicks-search)とECS(dev-newspicks-search-app)を用意し、(C)の場合は、dev-newspicks-searchとdev-newspicks-search-appを参照する。(B)の場合は、独自のECSを構築しdev-newspicks-searchを参照するsearch-appをECSにdeploy、(A)の場合は、独自のECSと独自のOpenSearchを構築し、独自のOpenSearchを参照するsearch-appを独自のECSへとdeployします。(A)(B)(C)を兼ね備えた最終的なインフラ構成図がこちらです。

図のようなインフラを構築してあげることで、開発に必要なリソースだけを構築することになりコストの最適化ができます。また、インフラ構築後で要件が変わることもあります。例えば(A)だったけど検索サーバーの開発や検索データの開発がしたくなったので(B)(C)にしたい場合や、(C)だったけど開発が終わったので(A)(B)にしてコストを抑えたい場合とかですね。このような場合についての変更も簡単で、cdkで管理されているため不要なリソースの設定値を外し、DNSのターゲットを変更するだけで可能です。つまり検索基盤の変更だけで済むため、検索機能の参照系では変更をする必要がありません。これもこのインフラ構成の利点です。
次に「index作成処理の問題」についてです。設計段階では、実行時間の長さと本番と同等のindexを作成することはできないことを受け入れていましたが、弊社で行われていたSnowflake移行プロジェクトがこの問題を解決します。この基盤改善を実装している間、弊社ではRedshift -> Snowflakeへの移行プロジェクトが進んでいました。Snowflakeにはゼロコピークローンというデータベース・スキーマ・テーブルなどのコピー機能があります。この機能の特徴は非常に高速なデータ復元が実現できることです。弊社では、この機能を利用して本番Snowflakeから開発環境Snowflakeへ定期的なデータ同期が実行されていました。 当初dev環境のRDSやDynamoDBからRedshiftにデータ同期を行う処理が必要でしたが、Snowflakeを利用することでこの処理は不要となります。また本番Snowflakeをコピーしたデータを利用するため限りなく本番に近い状態のindexを作成することができます。(実は、5分に一度のindex更新処理も存在するため本番環境と完全に同等のindexを作成することはできません)
また注意点として、NewsPicksにはさまざまな検索機能があります。個人情報保護の観点から、今回はindexに個人情報が含まれることのない、movie、news、bookを対象として処理を作成しました。
最終的なindex作成処理は次のとおりです。

このインフラとindex処理を実装することで全てのdev環境で効率よくかつコスパ良く限りなく本番と近いindexを持った検索基盤を構築することができ、開発者体験の向上が見込めるようになります!!
今回、実装に使用した「OpenSearch」や「Snowflake」 の技術、また検索基盤等については弊社の過去ブログで紹介されているためこちらでは説明しません。是非次のブログを読んでみてください!一部を紹介させてもらいます!
実装後のよかった点
早速ですが、実装後のよかった点についてです。 実装してみて以下のような変化がありました。
- 全てのdev環境で検索ページが動作するようになった。
- 開発者体験の向上と今後のメンテナンス性の向上により価値提供の速度が上がると見込める
- リソースの最適化によるコストの最適化を行ったことによりコスト削減につながった
- 従来のインフラで構築するよりもコストが下がり、リソースの数も最小限で済んだ
- 柔軟かつシンプルなインフラ構成にしたことにより、開発者が持つ選択肢が増えた。
- 使用する環境で必要なものだけを構築することが選択可能になったことで、運用の利便性やメンテナンス性も向上
まとめ
今回のまとめです。今回は、従来のインフラ構成を見直すことにより、さまざまなコストが高かった検索基盤をコスパの良い効率的なインフラ構成にしたことで、全てのdev環境で検索機能が使えるようにしたお話でした。結果として、検索ページが使えるようになり開発者体験の向上につながったことで、さらなる機能開発の速度向上や価値提供の機会増加が見込めるようになったかと思います!! これからも事業の継続的な価値提供のために、開発者体験や普段の運用負担軽減等の改善に励んでいきたいと思います。 ここまで読んでいただきありがとうございました!!