こちらの記事は以前にNewsPicks Tech Guideに投稿された記事をインポートしたものです。元の記事はid:satorishによって書かれました。
今回は、QCon NY 2019レポート(Day 1)で予告した ML for Data Systems セッションの参加レポートです。登壇者は Google Brain SIR から Alex Beutel さんです。
コンピュータの基礎アルゴリズムである 木構造 や ハッシュテーブル は、古典的で安定した理論である一方、昨今のコンピュータ計算資源の潤沢化に伴うような急進的な技術発展は見られていません。このセッションは、機械学習をデータ構造理論に応用し、性能の大幅改善を図るという野心的なテーマを扱います。
なお、この記事の内容は当該セッションと登壇者共著論文 The Case for Learned Index Structures に基づきます。

TL;DR
「データ構造」は、機械学習の文脈で言うところのモデルです。たとえば B木 は、キー値入力に対してソート済みインデックスを返す「モデル」と言えます。Alex は、Tensorflow によるニューラルネットワークを用いて、ポピュラーなデータ構造の大幅な性能改善を行いました。
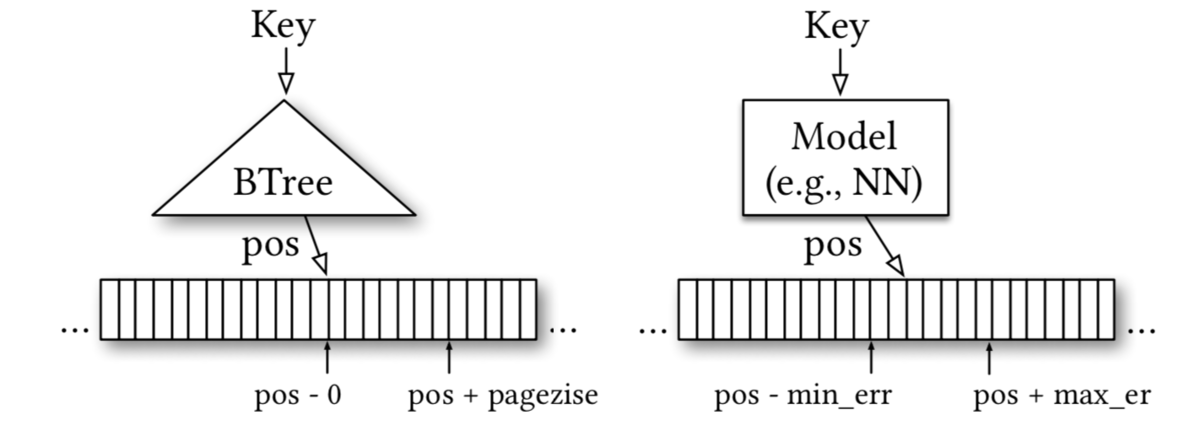
The Case for Learned Index Structuresより
B木の置き換えでは、メモリ使用量を 最大 99% 削減し、最大 2.7 倍の高速化を実現しました。
ハッシュテーブルの置き換えでは、ハッシュ衝突率を 最大 77% を削減しました。
ブルームフィルタの置き換えでは、0.5%偽陽性条件下においてメモリを 36% 削減しました。
いずれの結果もGPUを使用 しない 条件下での結果ですので、ハードウェアによる最適化でさらに効率的なモデルを生成できるかもしれません。
着想
B木をどうやってニューラルネットワークに置き換えたのでしょうか。
そもそも、B木は多分岐の平衡木で、リレーショナルデータベースのインデックス実装によく用いられます。つまり キー値から効率的に保存位置を特定する データ構造です。
B木はノードに複数のキーが保持でき、ノードに保持されている値より探しているキーが大きいか小さいかチェックして子を探していきます。B木は 再帰 を使って実装することができます。
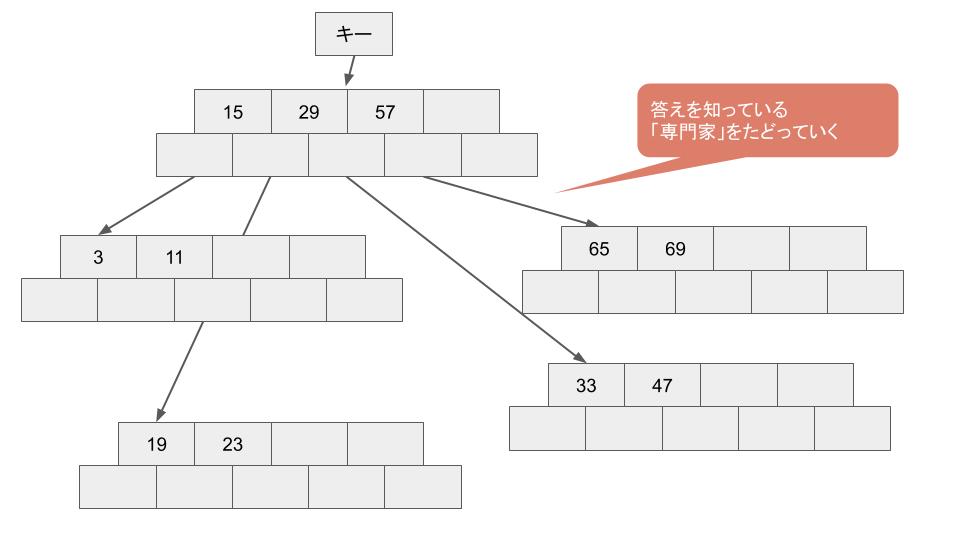
値は ITMediaの記事 より引用
Alex はニューラルネットワークによるモデルも 再帰的に 配置しました。各ノードがある種の 専門家 として、次のノードが誰になるべきか教えることで、最終的なゴールに到達します。ここで最悪ケースではB木にたどりつき、従来通りの方法で求める値に到達します。このとき各ノードは、入力の分布をあらかじめ知っているので、より効率的に 次のノードへ案内することができます。Alex は、この 専門家ノード を 再帰的 に配置することで、従来のB木よりも効率の良いデータ構造を表現できるのではないかと考えました。

転換点
ニューラルネットワークは計算リソースを大量に費やすフレームワークですので、Alex が求める「より早くより省エネな」アルゴリズムを実現するには適していません。一方で、ある種のデータパターンからモデルを自立的に学習できます。そこで Alex は、学習はニューラルネットワークを使い、推論は学習結果の最適モデルを用いることで、この問題を解決しました。
実験結果
B木の置き換え
B木と Learned Index の比較実験結果は以下の通りです。なお、Weblog は大学のウェブサイトの数年間分のデータで、2億行あります。Maps は地図の緯度経度データで、20億行あります。Log-Normal は対数正規分布から 19億行サンプリングしたものです。
| Weblog | サイズ (MB) | 検索(nano sec) |
|---|---|---|
| B木(ページサイズ 128) | 12.98 | 260 |
| Learned Index(2nd stage size = 100k) | 0.15 | 222 |
| Maps | サイズ (MB) | 検索(nano sec) |
|---|---|---|
| B木(ページサイズ 128) | 13.11 | 265 |
| Learned Index(2nd stage size = 100k) | 0.15 | 98 |
| Log-Normal | サイズ (MB) | 検索(nano sec) |
|---|---|---|
| B木(ページサイズ 128) | 12.46 | 263 |
| Learned Index(2nd stage size = 100k) | 0.15 | 178 |
The Case for Learned Index Structuresより
大きな表の一部を抜き出してあります。比較しているB木は C++ の stx::btree に近いプロダクションクオリティの実装を採用していますが、これよりもデータサイズも検索速度も上回っています。Maps では、メモリ使用量が 13.11MB から 0.15MB と、実に 99% メモリが圧縮されています。
Weblog は、授業時間、週末、長期休暇などに合わせて傾向が変化するため、難しい学習となり、あまり検索速度は向上していません。Maps は反対にイレギュラーが少ないので、データは多いですが平易な学習となり、検索速度が大きく向上しています。
ちなみに挿入・削除については提案手法があるものの、未解決問題として残っているとのことでした。
ハッシュテーブルの置き換え
ハッシュテーブルは Java の Hash-map 実装などでもおなじみの、キーに対する値を素早く参照するためのデータ構造です。ハッシュテーブルでは、誕生日のパラドクス で説明されるように、直感より衝突が起こりやすく、衝突のたびに高コストな LinkedList を使う必要があります。Learned Hash-map は事前分布を学習することで、この衝突をより効率的に避けることができると期待できます。

The Case for Learned Index Structuresより
B木の時と同様の検証データで、下記の結果が出ました。
| Hash-map 衝突率 | Learned Hash-map 衝突率 | 衝突減少率 | |
|---|---|---|---|
| Weblog | 35.3% | 24.7% | 30.0% |
| Maps | 35.3% | 07.9% | 77.5% |
| Log Normal | 35.4% | 25.9% | 26.7% |
The Case for Learned Index Structuresより
Hash-map はほとんど同じ衝突率で、1/3は衝突していますが、 Learned Hash-map 最悪のケースでも 25.9% しか衝突していません。
計算速度は従来の Hash-map の方が速く、そのため衝突の少ない Cuckoo Hashing などの方が依然として良い選択ではあります。さらにデータ量を大きくすると Learned Hash-map のほうが有利になっていくそうです。
ブルームフィルタの置き換え
ブルームフィルタは、キーが存在するかテストする確率的データ構造です。キーを問い合わせると「おそらく存在する」か「確実に存在しない」のどちらかがわかります。(偽陽性率はある程度あり、偽陰性率はゼロということです。)
ブルームフィルタを Learned filter で置き換えるに際しては、他の2つと少し戦略が変わります。学習対象がキーと非キーであるため、非キーの分布 を仮定しなければならないからです。ここでは非キーの分布は、過去の時系列データに見られるとし、将来も非キーは同じ分布に従うと仮定します。また、ブルームフィルタと代替品となるために、偽陰性率がゼロであることを保障するため、下記に示すようなハイブリッド型のフィルタを実装しました。

The Case for Learned Index Structuresより
比較実験では、ブラックリストに載ったフィッシングURLであるかどうか判別させます。Googleの公開レポートに含まれる、170万個のURLがキーとなります。非キーは有効である任意のURLと、ホワイトリストに載っている(フィッシングURLと間違われてしまった)URLで構成されます。モデルには文字レベル RNN が採用されました。

The Case for Learned Index Structuresより
図中 W は RNN の幅(Width)で、E は Embedding サイズです。偽陽性率が 1% であるとき、通常ブルームフィルタは 2.04MB 消費します。Learned Filter の場合は偽陽性率が 0.5% の場合でも、36% メモリを削減できました。
まとめ
機械学習によって、古典的アルゴリズムがどのように置き換えられるか検証しました。実用化に向けては課題が残っていますが、大きなアドバンテージを得ることができる可能性が十分示されていると思います。また、今回対象となっていないアルゴリズムの置き換えも十分考えられます。なお、本研究は実験段階で、実環境投入はまだされていません。
Tensorflowのような応用技術は、ハッシュマップなどのデータ構造を基礎として成り立っています。また確率的データ構造でないハッシュマップをニューラルネットワークで置き換えるための工夫は、とても示唆に富むものだと思います。
合わせて読みたい
NewsPicks にも Google に関連する読み応えのある記事がたくさんあります。是非ご覧ください。