Uzabase Saas Product Divisionフェローの矢野です。
この記事は、Rich Hickey(プログラミング言語Clojure作者)のプレゼンテーションSimple Made Easyへと繋がっていく、Ben MoseleyとPeter Marksによる「Out of the tar pit」というシステム設計について論じた論文の内容について説明したもので、ユーザベースのSaas Productでのテック発表の一つとしてプレゼンしたものを、ブログとして再度まとめたものです。プレゼン自体は25分くらいでしたので、おそらくこの記事の方がプレゼンよりも詳しいと思います。
- ソフトウェア危機
- ソフトウェアは本質的に複雑
- ソフトウェアの複雑さはどこから来るのか?
- 複雑さは、別の複雑さを産む
- 複雑さを分類する
- どうやって複雑さを扱うのか
- FRPシステム
- いま知っているシステムデザインに適用して考えてみる
- さらに
ソフトウェア危機
プログラミングとシステムデザインの方法論は、『構造化プログラミング』の時代から徐々に発達してきた、歴史の流れがあって、今見えている最高に人気のある手法も、そのような歴史の流れの末端です。直接の影響はなくとも、たくさんの生まれてきた設計理論が、互いに直接的に間接的に影響を与えてきて、今ができています。
Out of the tar pitは、Clojure作成時にRich Hickeyが影響を受けたという、2006年の論文です。主に関数型プログラミング界隈、特にLISP界隈で話題になることが多い印象ですが、おそらくは、論文内でいろんなプログラミング言語スタイルを比較して、関数型言語に重点を置いて論が進むからでしょう。
この論文は、ソフトウェアシステムの「複雑さ」を紐解き、複雑さには種類があること、それを知れば複雑さをコントロールできることを説いています。ただ、その話に入る前段として、ブルックスの有名な論考『銀の弾などない』について話す必要があります。
ソフトウェアは本質的に複雑
ブルックスの有名な本『人月の神話』のなかに「銀の弾などない-本質と偶有」という章があります。ブルックスは、この論考で、コンピュータシステムは本質的に複雑なのだと書いています。
ソフトウェアの複雑性は本質的な性質であって、偶有的なものではない
『人月の神話 新装版』フレデリック・P・ブルックス, Jr. 著 ピアソン・エディケーション 2002年 p169
さらに
複雑性を取り去ったソフトウェア実体の記述は、しばしばその本質も取り去ることになる。 数学や物理学は、複雑な現象を単純化したモデルを構成し、そのモデルからある性質を引き出し、実験的にその性質を証明することで、三世紀にわたって偉大な進歩を遂げた。この方法でうまくいったのは、モデルで無視された複雑性が現象の本質的な性質ではなかったからだ。複雑性が本質である場合には、この方法は使えない
『人月の神話 新装版』フレデリック・P・ブルックス, Jr. 著 ピアソン・エディケーション 2002年 p169
数学は複雑な現象を大きく単純化して扱うけれども、それができるのは、省いた複雑さが、現象の本質とは関係がない、捨ててもいいところだったからであって、ソフトウェアの場合は複雑性は本質的なものだから、この方法は使えないのだ、と言っているのです。
この言説に「それは違うでしょう」と言っているのが、Out of the tar pitです。
「Out of the tar pit」の「The tar pit」というのは、ブルックスの『人月の神話』の、第一章のタイトルです(日本語版では『タールの沼』)。 ソフトウェアは複雑だが、その複雑さには種類があり、コントロールできる、というのがこの論文の主張です。この論文は、ブルックスへのアンサーソングなんです。
ソフトウェアの複雑さはどこから来るのか?
今は当たり前のように言われていますが、ソフトウェアの複雑性の多くは「状態(ステート)」から来ます。この「状態」を含め、論文では、原因を大きく4つに分けて説明しています。
- 状態
- コントロール
- プログラムサイズ
- プログラミング言語がパワフルすぎる
プログラムが「複雑」である、というのはどういうことでしょうか。プログラムを見た時に、何をやっているのか、推論が効きにくい、もしくはまったくできない状態です。
状態は、時間によって変化していくので、この状態を使ったプログラムは、絶えず動作が変化します。なので、状態がどう変化するのかを知らなければ、プログラムの動作を推論することもできません。
そこにコントロール、つまり制御構文が加わります。変化する状態に、IF文などの分岐が加わると、さらに複雑さは増します。状態は変化する上に、その状態を使って分岐するのですから、プログラムの動作を推測することは、かなり難しくなります。
このようなコードが積み重なって巨大になると、全体の動作はほぼ推論不能になるでしょう。
この論文は2006年のものですから、Clean Architectureとかもまだありませんが、Clean Architectureを含めた設計手法が、プログラムの動作が推論可能になるように、プログラムを役割ごとに区分けしていることはわかると思います。この論文も、「複雑さ」の分析をもとに、違う考え方で、ソフトウェアを分割し統合しようとしています。
最後にある「プログラミング言語がパワフルすぎる」というのは、そもそも「プログラミング言語がなんでもできてしまう」のが複雑さを増しているという見解です。なんでも自由にできる、というのはパワーです。C言語ではメモリを自由に確保・開放できます。一方、ガーベージ・コレクタは、メモリを自由に確保するパワーを手放す代わりに、「メモリ管理」の必要性をソフトウェアから除外しました。パワーを抑えることは、複雑さの抑制に役立つ、という主張なのです。この辺りは、実際のシステムの区分けのところで、再度詳細を見ていきます。
複雑さは、別の複雑さを産む
状態とコントロールの話でも見られるように、「状態」という複雑さの要因が、「コントロール」という複雑さと合わさると、変化する状態によって分岐するプログラム、という、より複雑なものに進化してしまいます。複雑さは、別の複雑さを産んでしまうのです。だから、あらゆる手を尽くして、複雑さをソフトウェアから除去し続けなければいけません。シンプルであり続けなければいけません。
"Simplicity is HARD" (シンプルであることは難しい)
シンプルであり続けるには、不断の努力が必要です。ひとつの妥協により取り込まれた複雑さが、別の複雑さを産み出してしまうからです。
ではどうやって複雑さに立ち向かえばいいのでしょう。 状態とコントロールは、ソフトウェアを複雑にします。 でも、コンピュータ・システムというのは、究極的には、ユーザーが管理したい状態(ステート)を制御(コントロール)するためのものなので、この2つは絶対にシステムから消えてなくなったりはしないのです。
僕らの使うプログラミング言語の中には、変数を不変にしたり、オブジェクトステートを不変にする機能を持っているものも存在します。あるいは関数型言語であれば、「オブジェクト」様の存在はなくて、関数は引数にだけ依存し、引数は不変だったりします(実際のところ、この論文でも、さまざまなプログラミング手法が検討され、関数型言語が他よりも状態やコントロールをうまく安全に扱える、としています)。
ですが、依然としてアプリケーションにはステートが存在します。あるいは、「変数が変化する」代わりに、「不変値のリストとして、状態の変更を管理する」という方式に変わっただけで、結局それは状態なのではないか?ということもあるでしょう。どのような形態であれ、システムに状態は存在するのです。
複雑さを分類する
しかし、複雑さには、種類があります。
- 必須の(Essential)複雑さ
- 付随的な(Accidental)複雑さ
「必須の」「付随的な」という訳については、この記事を書いている僕が勝手につけました。重要なのは、この言葉は、ブルックス『銀の弾などない』に対応したワードだということです。
タイトルの「銀の弾などない-本質と偶有」や、「ソフトウェアの複雑性は本質的な性質であって、偶有的なものではない」という文言にある「本質」が、英語原文ではEssentialであり、「偶有」がAccidentalです。Out of the tar pitが使う「Essential」「Accidental」という言葉は、ブルックスの使った言葉を参照しています。この論文は、そもそもが『銀の弾などない』で言われた「ソフトウェアの複雑性は本質的なものである」という主張を退けようというものですから、同じ言葉を使って語っているのです。
英語では、ブルックスも、Out of the tar pitでも、「Essential Complexity」とか「Accidental Complexity」と表現しています。これをどう訳すか。
本文の内容的には、Essentialは「必須である」という意味で(この訳自体は辞書にも記載のある訳です)、Accidentalはその逆の「必須ではない」という意味で使われています。「必須ではない」という意味を込めて、「付随的」と表現することにしました。
「必須の複雑さ」と「本質的な複雑さ」とでは、語感としてだいぶん異なる感じがします(後者の方がより強く感じる)が、「本質的な複雑さ」と言ってしまうと、現実とはかけ離れた、理想を語っているような感じも受けてしまいます。 Out of the tar pitは、現実のシステムの構築についての意見を述べているものなので、より身近な、現実のシステムの話として捉える意味でも「必須の複雑さ」という訳を使いました。これ以降は、「必須の複雑さ」「付随的な複雑さ」という表現を使っていきます。
本当に必要な複雑さと、そうでないものがある
システムの複雑さには「必須のもの」と「付随的なもの」がある、というのが、この論文の土台となる主張です。 必須の複雑さとは
ユーザーの課題や要求(本文では Input と表現されています)から直接導き出せるもの
です。 逆に、付随的な複雑さとは、
それ以外すべて!
です。
これだけだと、何も言っていないのに等しいので、もう少し詳しく見ていきましょう。
キャッシュやカウンターやスレッドプールは、ユーザーの課題とは関係がないので、付随的です。
本文では、「ユーザーが、その言葉を聞いても、それがなんなのかわからないようなものは、すべて付随的と考えるべき」と主張されています。プログラムの詳細について知らないし専門知識もないユーザーにとっては、キャッシュやカウンターやスレッドプールは、それがなんなのかすら分からないし、気にする必要のないものです。今時の言い方をすれば、「ビジネスロジックと関係がない」ので、付随的なのです。
ユーザーの入力から派生して作れるデータは、すべて付随的です。 年齢は付随的です。誕生日と現在日時から計算できる派生データだからです。 ゲームにおける、自キャラの「現在地」は付随的です。スタート地点と、それまでの操作履歴から計算できるからです。
制御構文(コントロール)はすべて付随的です。 でも、IFなどの分岐が、ユーザーの直接の要求であるケースもあるのでは? ゴールド会員はポイント2倍とか。 でも、世の中にはロジック・プログラミングという分野があり、Prologのようなプログラミング言語では、「条件式(コントロール」を書くのではなく、事実を並べることによってプログラミングしていくことも可能です。コントロール構文なしでプログラムが書ける環境が実在する以上、コントロールはすべて、システムのユーザーにとっては、付随的と考えるべきだ、と著者らは主張しています。
とはいえ、付随的だからといって、重要なものもあるのではないでしょうか? 例えばパフォーマンスとか。現実問題として、ゲームで、キャラの現在地を毎回計算していたら、パフォーマンスが大幅に劣化しそうです。
もちろんです。もちろん、その通りなのです。
どうやって複雑さを扱うのか
複雑さの種類を見てきましたが、「必須」「付随的」と言われても、これらをどう扱えばいいのでしょうか。 「必須」か「付随的」か、の切り分けは、それが本当にシステムにとって役に立たない、という意味ではなりません。ただ、両者を区別する必要がある、ということなのです。両者を混ぜないこと。必須なものと、付随的なものを分離すること。必須であるかどうかと、役に立つかどうかとは、互いに関係がないことがらだから、ちゃんと区別しよう、という話なのです。
複雑さを扱う方法は、実質、2つしかありません
- 分割する(split)
- 避ける(avoid)
複雑さをいくつかの考え方で分割し、必要ないところは捨ててしまうのです。そのためには、「必須」「付随的」をきちんと見極める必要があります。
状態/ロジック分割 (State/Logic Split)
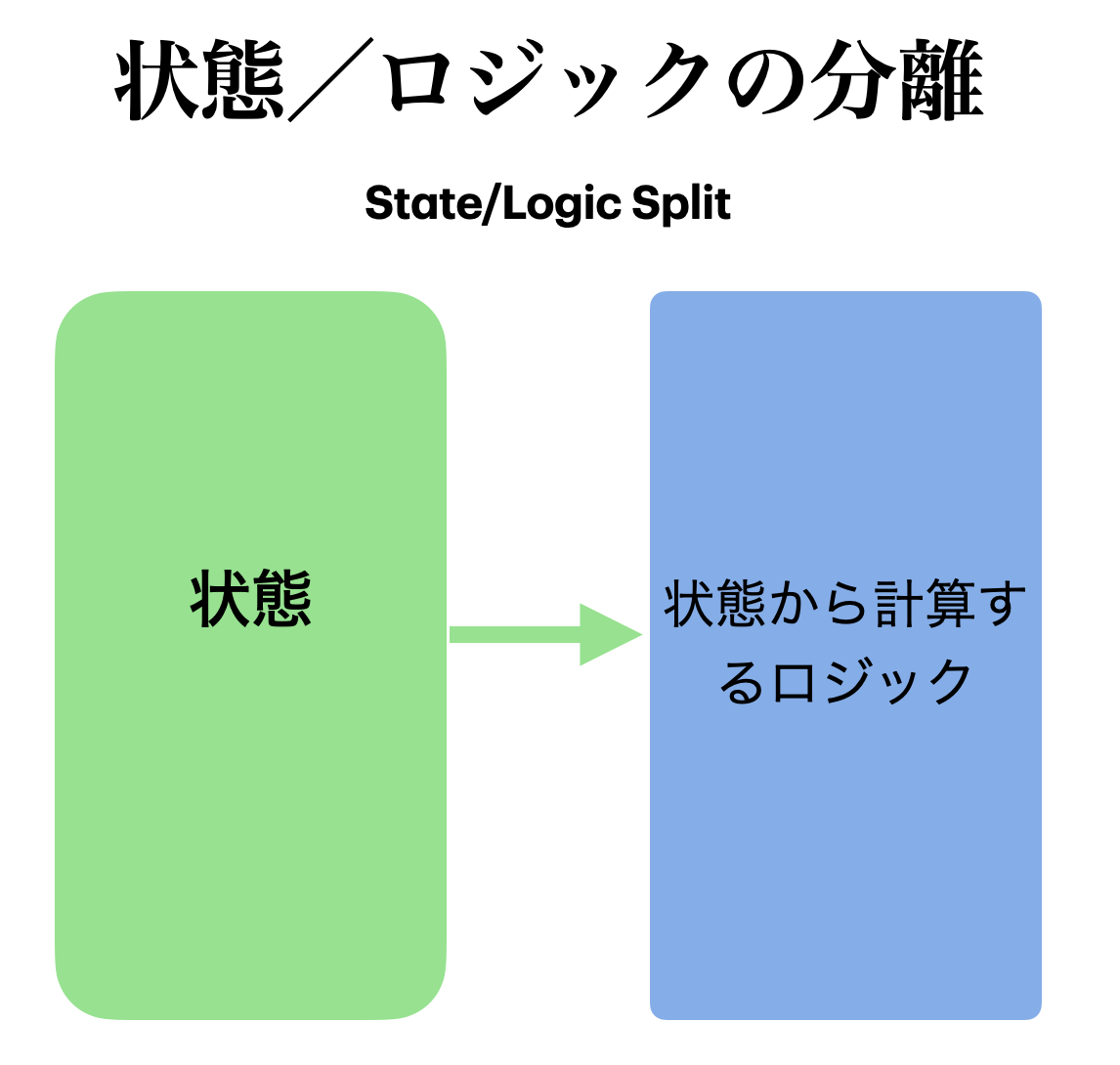
まず、システムが扱うべき「状態」から、ロジックを抽出して分割します。ここでいうロジックとは、状態から派生データを構築するようなもの、及び、いわゆるビジネスロジック(状態を操作するロジック)です。「状態」は複雑さの主な原因なので、可能な限り状態を減らすため、ロジックで表現できるものはロジックで表現するのです。
前述したように、「現在時刻」と「誕生日」から、「年齢」を計算することができます。これはロジックです。 スタート地点と移動履歴から、「現在地」を計算することができます。これもロジックです。
このように、状態からロジックを抽出していくと、なんとなく状態として扱ってしまっていたものが、実は状態ではなく、ロジックだということがわかってきます。年齢も、現在地も、状態ではなくロジックなのです。
この状態/ロジック分割を行う時には、システムは「理想的な世界」で動いているものと(敢えて)仮定します。理想的な世界では、計算時間はゼロです。僕らは、複雑な数式を見た時に、それらの「実行時間」を考えません。数式はあくまで理論を表現したものであって、「計算時間」などというものは存在しません。そういう前提でロジックを捉えることが大事です。そういう前提を持つことで、一見状態のように思える「現在地」が、実は「スタート地点」と「移動履歴」から計算できることに気がつくわけです。計算時間がゼロなら、ロジックとして扱えてしまうのです。
必須/付随分割 (Essential/Accidental Split)

次に、状態と、そこから抽出したロジックを、「必須なもの」と「付随的なもの」に分割します。
すでに見てきたように、「現在地」は状態ではなくロジックとして表現できるので、「現在地を計算するロジック」の方は「必須」側に入れます。一方、状態としての「現在地」は、(すでにロジックで計算できることがわかっているので)「付随的な状態」とみなしましょう。
「年齢」も「必須のロジック」と「付随的な状態」に分けられるでしょう。
このように分けていくことで、必要だと思っていた状態が、実はロジックで表現できる、付随的なものだったことが見えてきます。
付随的だが役に立つものの分割
これで、「必須」の側には、必要最小限の状態と、その状態をもとに計算するロジックが残ります。これらが本当にシステムに必要だったもの、です。 ただ、これはあくまで、計算時間がゼロの「理想的な世界」での分割に過ぎません。現実の世界で活用するために役に立つものが、付随的な複雑さの側に残っています。これらをさらに分割します。
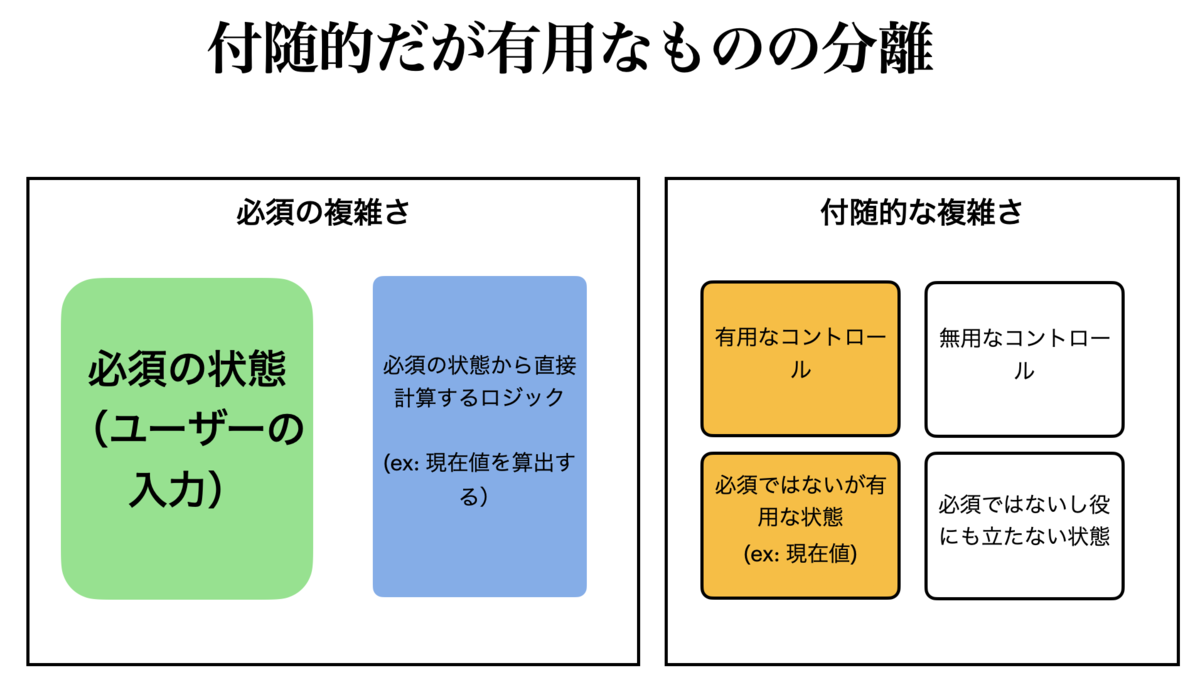
ここで、「付随的な状態」から、「現在地」を「付随的だが有用な状態」として切り出します。現在地はロジックですが、もし状態としてキープいていれば、システムにとって有用です。これはつまり、「現在地のキャッシュ」です。
そのほか、必要であれば「年齢」を切り出す手もありますが、年齢の計算くらいは一瞬なので、敢えて「付随的だが有用な状態」にも切り分けない、という判断もありでしょう。この場合、「年齢」は、「必須でもないし、有用でもない状態」として扱われます。必須のロジックとして「年齢を算出する」ロジックがあれば、状態としては不要ということです。
ここまで分割すると、システムにとって不要なものがはっきりします。図の一番右側にあるものは、システムにとって無用です。これらは捨てます。これらを捨てるのが、「分割する」「避ける」のうちの「避ける(avoid)」です。
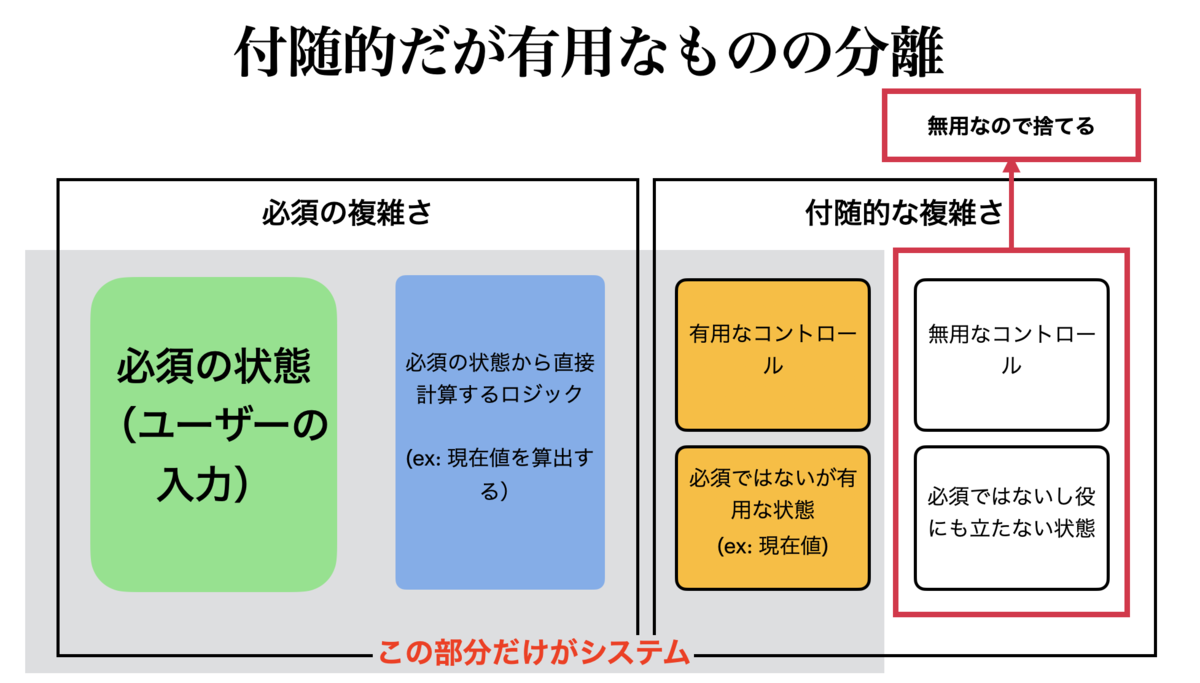
システムとは、図の左側、灰色に囲われた部分だけ、ということです。
システムを区分けする
付随的な複雑さは、あくまで「付随的」なものなので、この部分がなくてもシステムは動かなくてはいけません。必須ではないのですから、当然そうなります。つまり、「現在地」キャッシュがなくても、必須の複雑さに含まれる「現在地を算出する」ロジックがあるので、システムはちゃんと動かなければいけないのです。もちろんパフォーマンスが劣化する、などの副作用はあるかもしれませんが、ともあれ、システムは動くべきです。
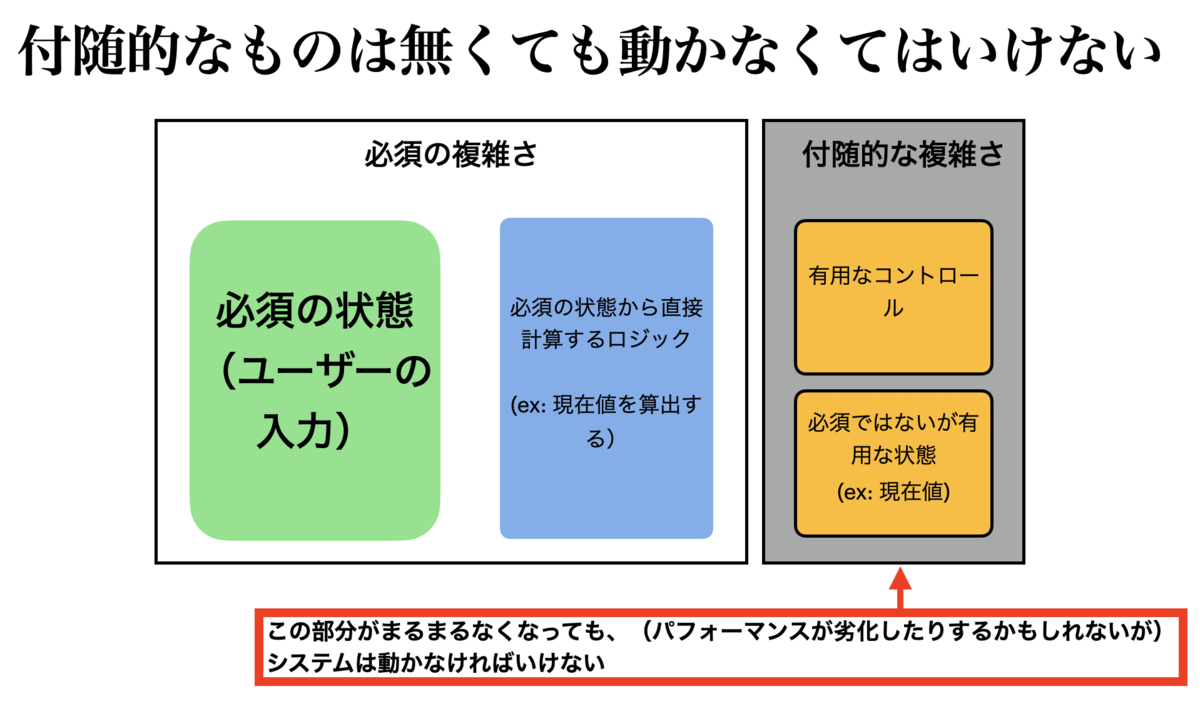
つまり、この部分は、システム本体から切り離し可能として、切り離しても動くように構成する必要がある、ということになります。
今まで分割してきた「必須の状態」「必須のロジック」「付随的だが役立つコントロール・状態」は、ただ分析として区別するだけではなく、システム内できちんと分割され、互いにアクセスを制限しなければいけません。

図の「外部境界」というのは、ユーザーインターフェースなどを想像してください。Webアプリケーションなどであれば、Controllerと呼ばれる層などです。あるいは、外側に出ていくものとして、ディスプレイへの表示などを考えてもいいでしょう。Clean Architecture的に言えば、Presenterです。
必須の状態は、他のどの部分にも依存してはいけません。この部分の変更は、他のあらゆる部分に影響を与えます。一方、他の部分の変更が、この部分に影響を与えてはいけません。
必須のロジックは必須の状態を利用して派生データを作り出したり、なんらかのビジネスロジックに従って状態を更新します。 この部分は状態にアクセスしますが、状態がロジックを参照することはありません。
「付随的な複雑さ」の部分は、前述のように、切り離し可能でなければいけません。この部分がなくても動かなくてはいけないのですから、この部分の変更が「必須の状態」や「必須のロジック」に影響を与えてはいけません。また、「必須の状態」や「必須のロジック」が、付随的な複雑さの領域にあるものにアクセスしてもいけません。繰り返しになりますが、この部分は切り離し可能なので、なくても動かなくてはいけないのです。
各部をどう扱うべきか
「必須の状態」部分(緑)に必要な機能は、状態を更新する機能と、状態から必要な情報を取り出す機能だけです。ここには、制御構文は必要ありません。
「必須のロジック」部分(青)は状態部が提供する機能で情報を取り出し、改変したり組み合わせたりして派生データを作り出します。必要な機能は、状態を組み合わせ派生させる機能と、派生データをもとに計算する関数です。
「付随的な複雑さ」部分(黄)は両者から完全に切り離されていなければいけません。
このように、各部ごとに、「やらなければいけないこと」が決まっているので、論文では、各部ごとに「すべきことしかできないように」すべき、と主張しています。かなりアグレッシブな意見ですね。各部ごとに専用のDSLを作ることまで想定しています。 これは「プログラミング言語がパワフルすぎる」問題を解決しようという提案です。なんでもできてしまうのが複雑さの要因なので、各部がすべきことしかできないようにしよう、ということなのです。
例えば、「付随的な複雑さ」部分は、切り離し可能なように「宣言的」であるべきと主張しています。 論文では宣言的な制約の記述方法などもサンプル的に載っていますが、意図するところは、「必須の状態」とも「必須のロジック」とも完全に切り離して、別のものとして記述すべきだし、その記述は詳細なプログラムではなく、宣言であるべき、ということです。その宣言的な記述は、アプリケーション・システムではなくて、インフラストラクチャ部分が解釈して処理すべきです。そうすることで、宣言的な記述はいつでも切り離し可能で、なおかつその詳細は完全にアプリケーション・システムから切り離されている状態を作ることができます。
例えば、「現在地を算出するロジック」に対して、パフォーマンス・チューニングとして、付随的な状態「現在地キャッシュ」を導入するとします。これを、「現在地を算出するロジック」内に「キャッシュがあればそれを取得する」というプログラムを書いたり、状態「移動履歴」にデータが入るたびに「現在地キャッシュを更新する」というプログラムを書いたりするわけにはいきません。このキャッシュは付随的であり、切り離し可能でなければいけません。
ですから、別の定義ファイルなどに、宣言的に「現在地を算出するロジック」に「use_cache」などのメタデータを指定できるようにして、そのメタデータを見て、システムのインフラストラクチャが、キャッシュにデータを取りに行く、という構造にすべき、ということです。
例えばJavaのアノテーションを利用して、メソッドに@UseCacheがついていれば、フレームワークがロジックを呼び出す前にキャッシュを参照する、みたいな処理をイメージすればいいと思います。@UseCacheがついていなくとも、システムはちゃんと動きます。アノテーションを処理する仕組みを別途実装する必要が生じますが、「必須の状態」と「必須のロジック」から見ると、インフラストラクチャが勝手にやってくれることですので、一切影響を受けません。
例えば、JavaのSpringフレームワークが処理してくれる機能については、アプリケーション・システムからは完全に独立しており、もしその部分に何らかの手を入れるとしても、それはあくまで「Springフレームワークに手を入れている」のであって、アプリケーションとは分離されています。そのような構造を、意図的に、自分のシステムに持ち込もう、ということです。
分割作業で「付随的」と分割したものは、すべて、このような形で、システムのメインロジックと状態から切り離すべきだ、というわけです。
必須の状態部(緑色の枠の部分)は、状態の操作だけができるべきです。ですので、この領域を扱うプログラミング言語は、可能ならば、状態の定義や取得及び取得条件、更新や削除だけができて、一切の制御構文を持たないのが理想的です。
必須のロジック部分(青色の枠の部分)は逆に、状態の定義ができるべきではありません。状態の定義や取得などは、あくまで、「必須の状態」部分へアクセスする形で行われるべきです。この部分では、取得した状態の組み合わせ(つまり派生データの定義)、それを使った計算(関数)、ビジネスロジック的な制約の設定だけができるべきです。
画面への表示や入力の受付といった、外部とのアクセス部分(図の一番右側)は、例えば状態の変更を監視するObserver(状態が更新されたら画面に反映するような、システムのロジックから切り離された外部プログラム)であったり、ユーザー入力を「必須のロジック」経由での更新処理に変換するようなFeederとして、外部化する提案がされています。これらは、前者であれば、古いMVCモデルにおけるModelの更新をViewが監視しているような構造が似ていると思います。後者は、ウェブアプリケーションにおける「コントローラー」が行なっているような処理でしょうか。あくまで2つほど提案がされているだけで、それ以上の詳しい記載は論文にはありません。あくまで、システムの状態やロジックとは、分離して管理されるべき、という主張です。 逆に言えば、コアロジックはずっと同じまま、外部インタフェースなどいつでも変えられるべき、という主張とも考えられます。
複雑さは別の複雑さを産む
システムの複雑さを適切なレベルに管理にするには常に、
- 避ける
- 分割する
の2つを、システムデザインのトップレベルに据えなければなりません。 一つの複雑さは、別の複雑さを産んでしまいます。だから、システムから複雑さを取り除き、シンプルであり続けなければいけません。一つの妥協がシステム全体を複雑にする可能性があります。
"Simplicity is HARD"
と論文に書かれています。シンプルであるということは大変なんです。
「複雑なシステムから複雑さを取り除く」のと「シンプルさを重視してデザインされた遅いシステムのパフォーマンスを改善する」のとであれば、後者の方がきっとマシでしょう。そのためにはシステムの要素を把握する必要があります。
システムに本質的に必要な要素は
- 必須の状態(Essential State)
- 必須のロジック(Essential Logic)
の2つだけであり、それらを見極めなければいけません。見極めたら、それらをシステムの中で分割し、アクセスを制限しなければいけません。見極められているだけではダメなのです。分割することで、個別に対処することが可能になるのです。この論文が書いていることも、究極的にはそこに集約されると思います。
FRPシステム
この記事では詳細までは触れませんが、論文内では、Functional Relational Programming (FRP) というアイデアの提案が、概要レベルで紹介されています。 曰く、
- システムの「必須の状態」には関係モデルを採用する。なぜなら、関係モデルには、(オブジェクト構造に比べて)データへのアクセス順序をあらかじめ定義する必要がない、という利点があるから。ユーザー定義型および関係を定義するDSLを用意する
例
def alias Address : string
def alias name : string
def alias price : double
def enum roomType : KITCHEN | BATHROOM | LIVING_ROOM
def relvar Decision :: {address: Address, offerDate: Date, bidderName: Name, bidderAddress: Address, decisionDate: Date, accepted: Bool}
def relvar Room :: {address: Address, roomName: string, width: double, breadth: double, type: roomType}
- 「必須のロジック」は、定義した状態モデルを、(JOINのように)組み合わせたり、フィルタしたりする機能と、値を計算する関数と、ユーザー定義関数を定義する機能、及び、「モデルが満たさなければいけない制約」を定義する言語機能をDSLとして用意する
例
/* RoomInfo :: {address: Address, roomName: string, width: double, breadth: double, type: roomType, roomSize: double} */
RoomInfo = extends(Room, (roomSize = width * breadth))
/* Acceptance :: {address: Address, offerDate: Date, bidderName: Name, bidderAddress: Address, decisionDate: Date} */
Acceptance = project_away(restrict(Decision | accepted == true), accepted)
この例では、Acceptanceは、Decision全体からacceptedがtrueのものだけを抜き出したものから、acceptedフィールドを除外した(project away)もの、という定義をしています。論文では「コントロールは付随的」と言っていますから、あえて「宣言的に」派生データを書けるようにしているのでしょう。
- 「付随的な複雑さ」を扱う部分には、「必須のロジック」で定義した派生データに対して、外部的にタグ付けできるDSLを用意する(例えば、派生データをパフォーマンスのために保存したい場合には store というタグをつける)
例
declare store Acceptance
といった仕組みになっていました。関係モデルを土台に持ってきた関係で、派生データの定義はおおむね宣言的に定義できる仕組みになっていたり、なかなか面白いものです。少しだけ、例として記述しましたが、論文の方には、もう少し長い説明が載っています。
ただあくまで概要レベルの記述しかないため、複雑なビジネスロジックの実行やトランザクションなどをどう扱うか?についても考慮されていません。宣言的に定義したものをどうプログラムが処理するのかも、関係モデルで定義された「必須の状態」を、物理的にどう保存するかも当然書いてませんし、そもそもそれらは、今までに説明したシステム構造では「外部境界」に当たる部分ですから、この論文のメインテーマでもないということだと思います。例えばClean ArchitectureがGatewayの向こう側での詳しい詳細実装について何も語らないのと同じでしょう。システム全体をどう扱うか、どう分割するべきか、という話をしているのであって、分割した後、それらを処理するシステムのインフラストラクチャ部分を作るのは、開発者の仕事だということでしょう。
概要レベルではありますが、著者がどういうイメージで各部分を捉えているか?を把握するサンプルとしては、結構おもしろく読める部分だと思います。
また、上記の記述はあくまでサンプルと捉え、これらの宣言的記述を、あえて自分の好きな言語でやってみるとどんな感じになるか?とか、あるいは上記でstoreとタグづけされたAcceptance派生データ(ロジック)をフレームワーク部分がキャッシュとして保存する仕組みを、自分ならどう実装するか?とか、このアイデアを自分ならどう実装し、実装するにあたってどこにトレードオフを置くか?(汎用性を取って、DSLを定義するのは諦めて既存のプログラミング言語を使う、とか)などなど、自分でフレームワークを作るかのように考えていくと、結構学びがあり面白いと思います。
いま知っているシステムデザインに適用して考えてみる
Clean Architectureという有名な本のあの図を見てみましょう。
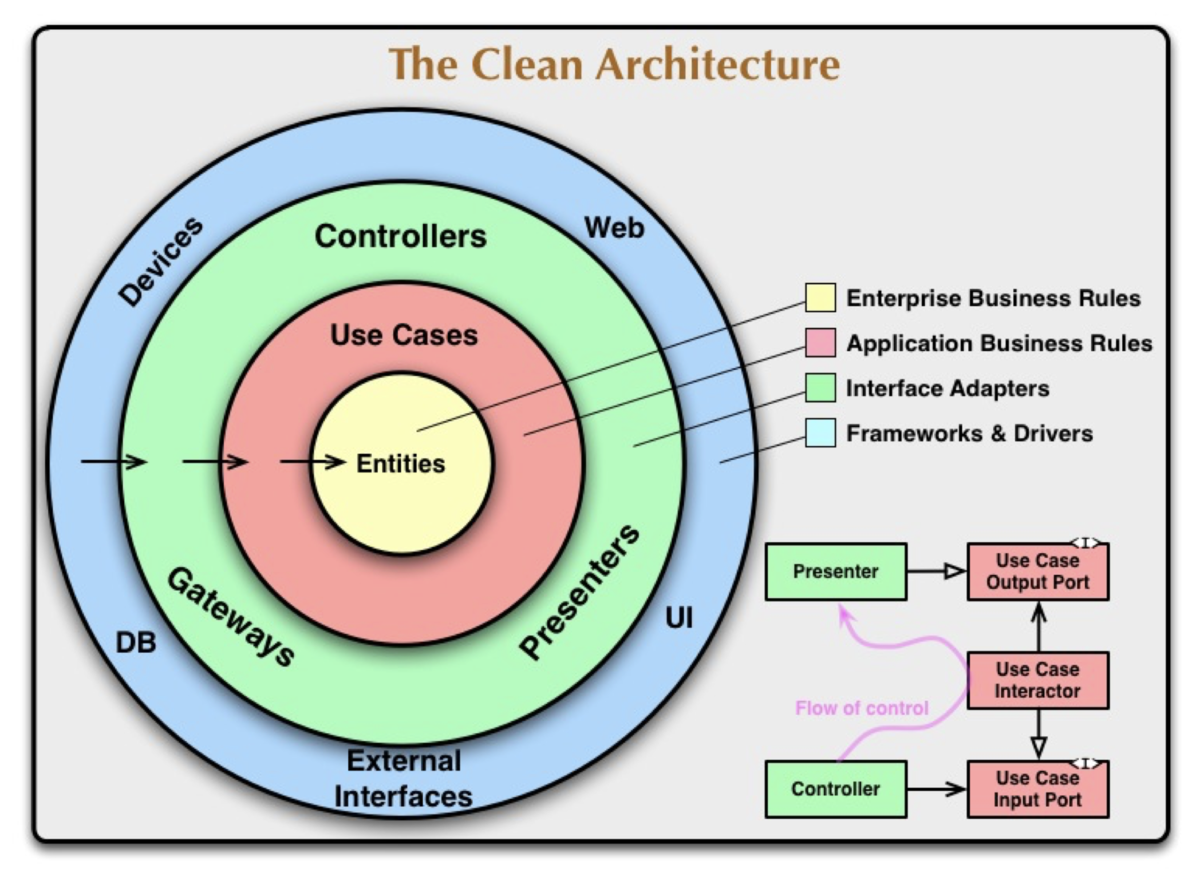
この図ばかり取り上げられてしまうのも問題だと思っているのですが、皆よく知っている図なので使います。 この図は、
「処理の流れは一方通行であるべき」 「外界(青)を扱う部分(緑)とシステムのコアロジック(赤・黄)は分割されているべき」 「状態(黄)を扱う部分はロジック(赤)と分離されているべき」
と言っていて、実は、今回取り上げたOut of the tar pitと似たことを言っているとも言えます。 というより、Clean Architectureを含む「Clean」シリーズ本(Clean Code, Clean Coderなど)は、特定テーマについて、過去に良いとされてきたものを紹介している本ですので、そのアーキテクチャ版であるClean Architectureは、過去のいろんな「良い」設計手法に共通している構造を紹介しているものでしょう。 Out of the tar pitが提案しているシステム構造も、そのような流れの一部で、やはり「良いデザイン」に共通している要素を持っている、ということです。
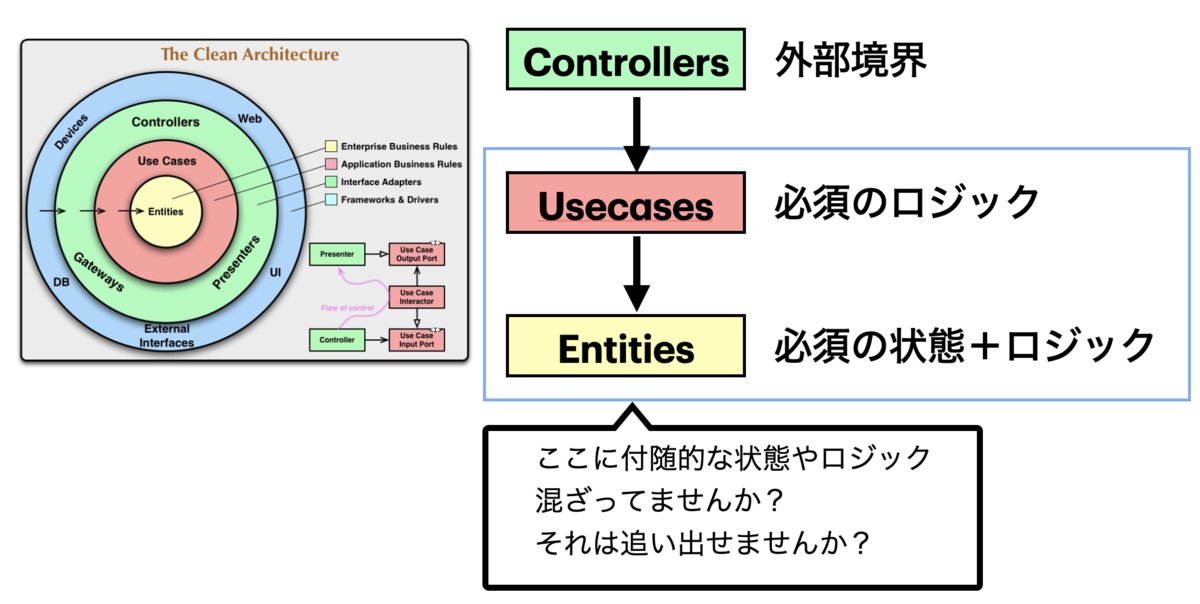
とはいえ、その差分をみると、自分の今のシステム構造がこれでいいのか、考えるきっかけになると思います。
Clean Architectureのあの図は、必須か付随的かについて扱っていません。自分がusecaseに定義したメソッドは、必須のロジックだけを扱っているでしょうか? キャッシュを書き換えてたりしないでしょうか? あるいは、Entities内で、必須の状態と、付随的な状態を区別できているでしょうか? オブジェクトは「年齢」というフィールドを持っていたりしないでしょうか? それがメソッドではなくてフィールドなのはなぜでしょうか? 生年月日から計算するメソッドにしたらダメでしょうか? そもそもあるエンティティA自体、必須の状態でしょうか? 付随的なものなら、システム外に追い出せないでしょうか?
新しい視点からみると、別の課題が見えてきます。そうすると、別の議論も生まれてきます。 システム設計にも歴史があって、システムデザインは、未だ解決できていないソフトウェア危機を解決しようという試みです。今最高と思ってる設計論もおそらくまた別の設計論で置き換えられるかもしれませんし、それは、まだ問題は解決してないからです。
システム設計論は複数あって良いし、あるべきと言ってもいい。 それでも、変わらない土台、というものはきっとあります。いろんな設計論を知り、それらについて議論することで、そう言った「変わらない土台」が固まっていくのだと思います。
また、設計論が生まれてきたいろんな経緯を知り、その上で本を読むと、今よりもっと楽しく読め、考え方も膨らみます。今回の論文を知った上でもう一度ブルックス先生の『銀の弾などない』を読むと、前に読んだ時とは別の趣きがあると思います
さらに
Out of the tar pitのテーマは「複雑さとはなにか」でした。この論文の中では、「シンプルであり続けなければいけない」とか Simplicity is HARD とか書かれているのですが、実は、「シンプルさとはなにか?」については何も語っていないのです。
それについて語ろうとしたのが、Rich Hickeyの『Simple Made Easy』(transcript)(解説)です。Rich HickeyはClojureについてOut of the tar pitの影響を受けたと言われており、自身のプレゼンでもこの論文について何度か言及しています。その流れとしてSimple Made Easyがあります。ブルックス先生の『銀の弾などない』から Out of the tar pit が生まれ、そして Simple Made Easy へと繋がっていく、という流れ、とても面白いですね。