みなさんこんにちは。株式会社ユーザベース SaaS事業 炭谷・酒井です。
Prometheusスケーリング問題とその解決策
自社の監視ツールとして、Prometheus採用しております。しかし、監視の規模が大きくなるにつれ、一部の構成にはスケーリングの限界があることが明らかとなってきました。この記事では、私たちが遭遇したスケーリングの問題と、それをどのように解決したのかを紹介します。
遭遇した問題
- GrafanaでPrometheusのデータを参照しようとすると、10分以上の期間が表示されない事象が起きました。この問題の原因は、Prometheusのメモリ不足によるものでした。
- 複数のユーザーが同時にGrafanaのダッシュボードを参照すると、Prometheusが停止してしまう事象が発生しました。これもメモリ不足が原因でした。
- 当初、Prometheusのメモリを増加させることでこれらの問題に対処していましたが、最終的に100GB以上のメモリが必要となる状況に陥りました。
既存の構成
- 各Kubernetesクラスタ内に配置されている子Prometheusが、親Prometheusからfederateされる形になっていました。(ここでの子Prometheusの役割は親PrometheusへのProxyとしての役割となっていた。)
- Grafanaは、全ての監視データが集約された親Prometheusのみを参照していました。
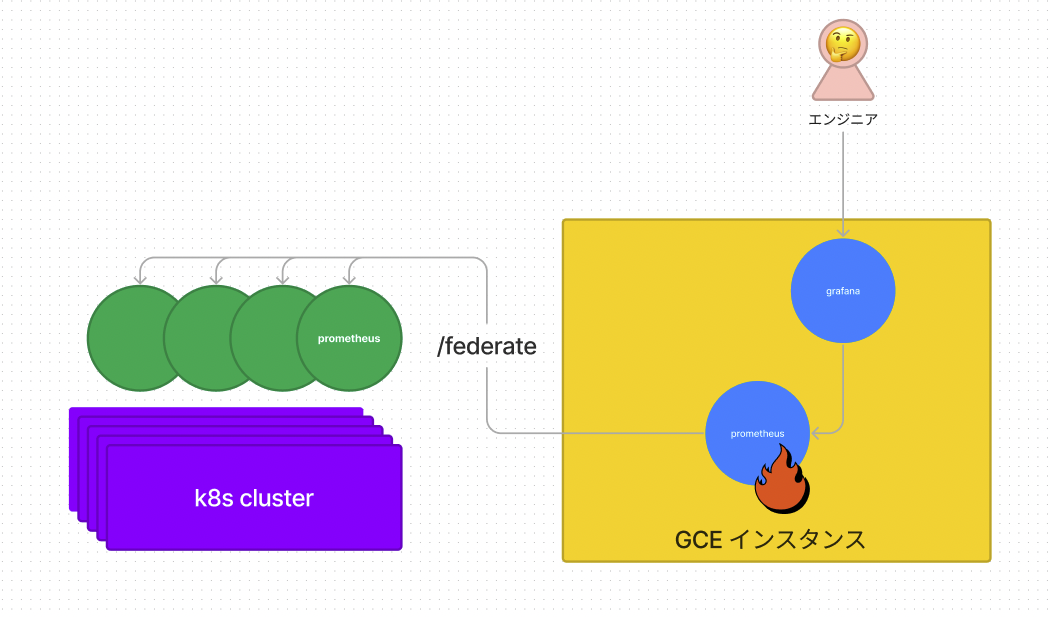
既存の構成
原因
この問題の主要な原因は、全ての監視データを親Prometheusに集約していたため、親Prometheusが大きくなりすぎ、スケーリングが難しくなってしまったことでした。Prometheusのfederate機能は、特定のメトリクスをデータセンター間で共有するためのもので、全メトリクスの集約を目的としたものではなく、federate機能を利用した垂直スケーリングには限界がきていました。
改善策
各Kubernetesクラスタ内のPrometheusは、親Prometheusからfederateされないように変更しました。これにより、Grafanaは直接各KubernetesクラスタのPrometheusを参照する形になりました。
ここは垂直スケーリングから水平スケーリングに変更した形となります。(子Prometheusは本来のPrometheusの機能としてメトリクスを取集して貯める役割を果たすようになりました。)

上記の変更により、メモリの問題が解消され、10分以上の期間も正常に参照できるようになりました。
また、既存の構成では親Prometheusが停止すると、全ての監視データが見えなくなる問題がありましたが、新しい構成ではその影響範囲を大幅に縮小することができました。
まとめ
今回Prometheusのスケーリング問題を解決するために、水平スケーリングでの構成に変更しました。 適切な構成とスケーリングの対応により、監視システムの安定性や効果を維持することができました。