はじめに
皆さんこんにちは! ソーシャル経済メディア「NewsPicks」プロダクトエンジニアの森田 (@moritama7431) です:) 私は2024年4月に株式会社ユーザベースに新卒入社し、現在は主にNewsPicksにおける推薦機能の開発改善に携わっています。
本記事では、NewsPicksにおける推薦システムの継続的改善を加速させるために、機械学習パイプラインの新規追加の学習コストと開発工数を大幅削減させることができた基盤改善の取り組みについて共有します。 実は昨年秋に取り組んでいた内容なので、もうすぐ1年経ってしまいます。しかし将来の自分自身やチームメンバーのためにも本取り組みを言語化・意味付けしておくべきだと、遅ればせながら一念発起し執筆してみました! なお本記事では、「機械学習パイプライン(以下、MLパイプライン)」を「機械学習システムにおける特徴量作成/学習/推論のいずれか、もしくはいくつかを行うデータパイプライン」と定義しています。
背景: 「A/Bテストしやすいシステムであること」は推薦の成果をスケールさせるために必須なんだ!
まず最初に、今回の取り組みの背景を共有します。
私たちは、プロダクトで推薦システムの成果を出して貢献していくために、推薦モデルの良し悪しを高い確度で評価できる実験を、簡単かつ安全に実行できる状態を作ることが重要だと考えています。 言い換えれば、「A/Bテストしやすいシステム」こそが、推薦システムの継続的改善と成果をスケールさせるために不可欠ということです。
この考えに至った経験談は、以下のブログ記事や登壇資料にて詳しく紹介しています。もし興味があればぜひ読んでみてください!
経験談の要約は以下です。
- 有望そうな新モデルを試したが、オフライン評価では既存モデルより悪く見え、導入判断が難航(後に「オフライン評価-オンライン評価が相関しない問題」に遭遇していたことが発覚!)。
- また、当時の推薦システム基盤はA/Bテストを安心安全に実施できる基盤が整っておらず、オンライン評価(A/Bテスト)や本番稼働に踏み切りづらかった。
- そこで、複数モデルを安全に並列運用できるA/Bテスト前提の構成へ推薦システム基盤を刷新。確度の低いオフライン評価への依存度を下げ、オンライン評価を実施しやすくした。
- 結果として、おすすめ枠のCTRを約1.2倍改善する新モデルを本番導入することができた!
というわけで、この経験以降、「A/Bテストしやすいシステムであるかどうか」は推薦システム基盤の開発・改善の際に常に意識すべき重要事項として、チームの共通認識となりました。
つまり、推薦システムの成果をスケールさせるためには、オンライン評価(A/Bテスト)を行いやすい環境が必須であり、そのためには新しいモデルを安全かつ簡単に本番投入できるMLパイプライン構築が不可欠、これが本取り組みの背景なのでした。
課題: 現状の推薦システム基盤では、MLパイプラインの追加が安全ではあるが面倒だった!
上述の背景を踏まえ、ここではNewsPicksの推薦システム基盤における課題感を共有します。
推薦システム基盤のアーキテクチャ紹介
NewsPicksの推薦システム基盤は、ざっくり以下のようなアーキテクチャで構成されています。
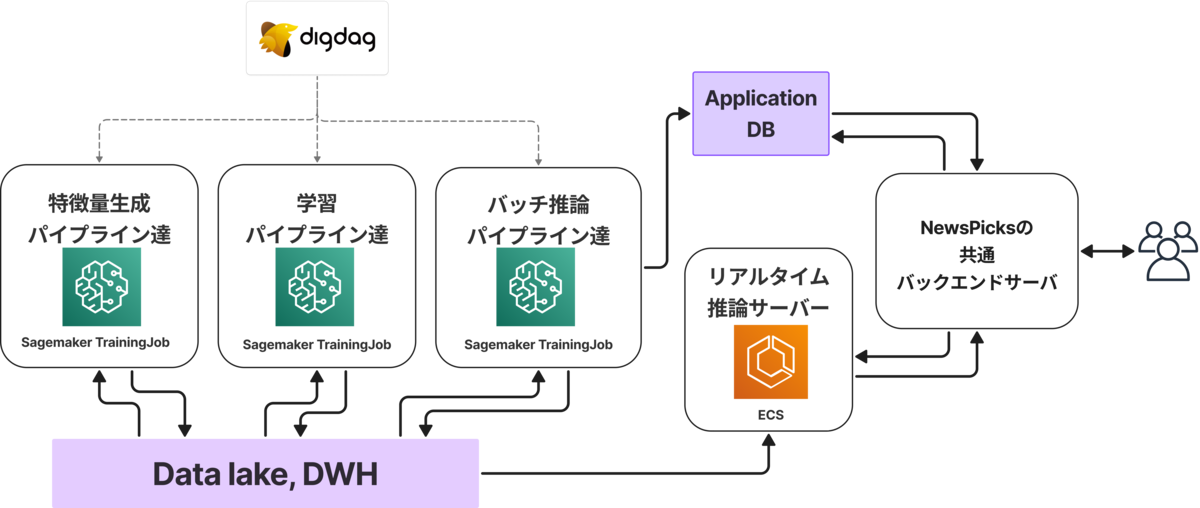
ここで上図から伝えたいのは、大きく以下2つの特徴です。
FTI Pipelinesアーキテクチャ的な構造
特徴量作成(Feature)・学習(Training)・推論(Inference)をそれぞれ独立したパイプラインとして構築し、Feature Storeなどの共通データ層を介して連携します。これにより、必要な計算リソースや実行タイミングが異なる各工程を分離して開発・改善・運用しやすくしています(参考: Hopsworks CEO Jim Dowling氏のブログ 「From MLOps to ML Systems with Feature/Training/Inference Pipelines The Mental Map for MLOps to align your Data-ML-Product Teams」)
MLパイプラインの運用にはワークフローサービス + フルマネージドな計算リソースの組み合わせを採用
ワークフロー管理には既存のデータ基盤でも利用しているDigdagを採用し、既存パイプラインとの連携や社内に蓄積された運用ノウハウをそのまま活用できます。 計算リソースはジョブ単位でオンデマンドに起動・解放されるようなフルマネージドな実行環境を採用しており、インフラの管理を最小限に、必要な時に必要な大きさの計算リソースを確保できます。さらに、複数モデルを同時に稼働させる場合でもリソース競合を避けることができます。特にML用途に最適化されたSageMaker TrainingJobを主に利用しており、AWS LambdaやFargateでは利用できないGPUなどのアクセラレーターを活用できる点が大きなメリットです。また、PoC時やバッチ学習など実行時間に厳密さを求めないケースでは、スポットインスタンスを有効化することでコストを大幅に削減できるのも採用理由です。
上記のようなアーキテクチャにより、既存モデルに影響を与えず、新しい推薦モデルのMLパイプラインを安全に追加でき、A/Bテストを安心して実施できます。
ただし一方で、新規パイプライン追加の手間と学習コストが高いという課題が残っていました。
もっとA/Bテストしやすい推薦システム基盤へ
現在のNewsPicksの推薦システム基盤は、前述のアーキテクチャにより「新モデル追加時の安全性」は確保できています。 しかし、「新モデル投入のしやすさ」という点で課題が残っていました。新しい推薦モデルをA/Bテスト可能な状態にするまでに、安全ではあるものの学習コストと開発工数が高いのです。
原因は大きく2つありました。
- MLパイプライン追加の学習コストが高く、SageMakerに一定精通したエンジニア(SageMaker職人)が必要
- パイプラインごとに異なる実行環境を指定するような運用になっており、開発手順が多かった!
原因1: MLパイプライン追加の学習コストが高く、SageMakerに一定精通したエンジニア(SageMaker職人)が必要!
1つ目の原因は、SageMakerに関する知識の学習コストが高かったことです。
我々はMLパイプライン用の計算リソースとしてAWSのマネージドバッチサービスSageMaker TrainingJobを利用していますが、実装がSageMakerのマネージド機能に強く依存していました。 より具体的には、入力データのダウンロード処理、出力データのアップロード処理、ハイパーパラメータの渡し方などをSageMakerのマネージドな処理に依存していました。そのため、例えば以下のように、SageMaker固有の仕様やお作法を理解してコードを書く必要がありました。
- 入力データのパスを環境変数
SM_CHANNEL_TRAININGから取得 - ハイパーパラメータを環境変数(例:
SM_HPS_LEARNING_RATE)から取得 - 学習後のモデルを
/opt/ml/model配下に保存
こうしたSageMaker特有の実装要件により、新しいパイプラインを追加するにはSageMakerの仕様を把握したSageMaker職人が必要で、結果として学習コストが高くなっていました。
原因2: パイプラインごとに異なる実行環境を指定するような運用になっており、開発手順が多かった!
2つ目の原因は、パイプラインごとに異なる実行環境(Pythonバージョンや依存パッケージなど)を指定していたため、パイプライン追加のための開発手順が多かったことです。
新しいMLパイプラインを追加するたびに、例えば以下のような作業が必要でした。
- Pythonバージョンの指定
- パッケージ依存関係の定義
- Dockerfileの作成
- 特徴量生成/学習/推論コードの実装を追加
- ECRリポジトリの追加(CDK)
- TrainingJob用IAMロールへのアクセス権限追加(CDK)
- CDパイプラインへのビルド&デプロイ処理追加(CDK)
さらに、MLパイプライン毎にPythonバージョンやパッケージ依存関係といった実行環境がバラバラになっていたため、似た処理があっても共通化しづらいという問題もありました。 その結果、パイプライン追加のたびに管理すべきリソースやコードが必要以上に増えてしまっていたのです。
課題解決: 基盤改善によりMLパイプライン追加の学習コストと開発工数を大幅削減!
先述の通り、MLパイプラインを追加して新しい推薦モデルをA/Bテスト可能な状態にするまでに、安全ではあるものの学習コストと開発工数が高いという課題がありました。
この課題を解消するため、次の2つの基盤改善を行いました。
- SageMaker TrainingJobの役割を単純化し、学習コストを削減!
- 全MLパイプラインのコンテナイメージを共通化し、開発手順を簡素化!
改善1: SageMaker TrainingJobの役割を単純化し、学習コストを削減!
1つ目の改善は、SageMaker TrainingJobの役割をシンプルに「指定したコンテナイメージを、指定したスペックのインスタンスで、指定したエントリーポイントで実行するだけ」に限定したことです。 これまで利用していた、入力データのダウンロードや出力データのアップロードといったSageMakerのマネージド機能はすべて自前で実装しました。 SageMakerの知識を抽象化クラスに情報隠蔽する案もありましたが、我々のユースケースではマネージド機能の恩恵が少なかったため、直接削る方がシンプルで良いと判断しました。
この変更によるメリット:
- 学習コストの低減: 開発者は「PythonでCLIアプリを作る方法」さえ知っていれば、新しいパイプラインを実装可能に。SageMaker特有の仕様理解は不要になった。
- 実行環境の柔軟性向上: SageMakerへの依存度が下がったことで、将来的に他の任意のコンテナサービスへ容易に移行可能。また、例えばバッチパイプラインはSageMaker TrainingJobで、ストリーミングパイプラインはLambdaで、といった用途別の使い分けも行いやすくなった。
- ローカル・CI環境での動作確認やテストが容易になった。
この変更によるデメリット:
- SageMakerのマネージドIO機能を利用できない: 特にマルチインスタンス実行時のデータ分割・統合機能は使えなくなる。
もっとも、現状のNewsPicksでは基本的にシングルインスタンス実行で運用しており、マネージドIOの恩恵はほぼ受けていません。そのため、メリットがデメリットを大きく上回ると判断しました。もし将来的にマルチインスタンスでの学習や推論が必要になった場合は、その時に対応方針を検討すればよいと考えています。
改善2: 全MLパイプラインのコンテナイメージを共通化し、開発手順を簡素化!
2つ目の改善は、すべてのMLパイプラインを単一のコンテナイメージに統合し、実行時にエントリーポイントを切り替える方式への変更です。

従来はパイプラインごとにDockerfileや依存定義(pyproject.toml)を持ち、Pythonバージョンや依存パッケージを別々に管理していました。 そのため、新しいパイプライン追加する際には、Dockerfile作成やECRリポジトリ追加、IAM設定など7ステップ以上の作業が必要で、環境管理も煩雑でした。
これを、Pythonバージョン・依存パッケージを共通化し、1つのコンテナイメージに全パイプラインのコードを集約する形に変更しました。SageMaker TrainingJobを起動する際には実行するCLIアプリ(エントリーポイント)を切り替えることで、任意のパイプラインの処理を実行します。 これにより、新規パイプライン追加時の手順はほぼ以下の2つだけになりました。
- 必要に応じて共通pyproject.tomlを更新(poetry add)
- 特徴量生成/学習/推論コードの実装を追加
この変更によるメリット:
- 手順の大幅簡素化:7ステップ → 2ステップに削減された。
- パイプライン間のコード共通化が容易に:コードの重複が減り、保守性・開発効率が向上した。
- CI/CD時間短縮:環境切替や複数イメージビルドが不要になり、ビルド・テスト時間が削減された(実際にCI/CDの実行時間が約1/3に短縮した!)。
この変更によるデメリット:
- パイプライン間の結合度が上がる(コンテナイメージの結合):
- 不要パッケージによるコンテナサイズ肥大
- あるパイプラインの変更が他へ影響するリスク
このデメリットについては慎重に検討しました。というのも、かつての旧推薦システム基盤ではパイプライン間が密結合だったため、新しいモデルを試す際に既存パイプラインへ副作用が発生するリスクが高く、実際にモデル改善サイクルが停滞した時期があったからです。 その経験から、今回の改善の試みにおいても結合リスクには注意が必要です。
しかし、現在のアーキテクチャでは依然としてMLパイプラインごとに計算リソースは完全に独立しているため、リソース競合は発生しません。また、単体テスト・統合テストの自動化により、コードレベルでの影響も早期に検知できる体制を整えています。 これらを踏まえて、今回の改善で得られる開発効率・保守性upのメリットはリスクを大きく上回ると判断しています。
結果: MLパイプライン追加の学習コストをほぼゼロ化し、開発工数を大幅削減できた!
今回の改善により、特にバッチ推論などバッチパイプラインのみで完結するようなユースケースでは、従来の2分の1以下の工数で、かつ学習コストほぼゼロで新しいMLパイプラインを追加・本番リリースできるようになりました。さらに、リアルタイム推論のユースケースでも、特徴量生成や学習はバッチパイプラインで運用しているため、同様に今回の開発効率改善の恩恵を受けられています。
実際、改善後に取り組んだある新規の推薦機能の開発では、わずか2日分の工数で本番稼働 & A/Bテストを実施可能な状態にまでリリースすることができました。 また、SageMakerやCDKの詳細を意識する必要がなくなったことで、データサイエンティストメンバー自身が本番パイプライン用のコードを直接開発しやすくなりました。
ちなみに、かの有名なMLシステムの技術的負債論文 (Hidden Technical Debt in Machine Learning Systems, Sculley et al., 2015)では、結論パートにて「MLシステムの健全性を測る5つの質問」が提案されています。 今回の成果は、その中でも次の2つに直結しています。
「How easily can an entirely new algorithmic approach be tested at full scale?(全く新しいアルゴリズムのアプローチを、どの程度簡単にfull scaleでテストできるか?)」
「How quickly can new members of the team be brought up to speed? (チームの新しいメンバーをいかに早くスピードアップさせることができるか?)」
(引用元: Hidden Technical Debt in Machine Learning Systems, Sculley et al., 2015)
もちろん、今回の変更には前述の通りデメリットも存在します。しかし全てのアーキテクチャはトレードオフです。少人数チームでNewsPicks内の様々な推薦アルゴリズムのユースケースたちを開発・改善・運用していくためには、有効な意思決定であったと考えています。
おわりに:
本記事では、NewsPicksの推薦システム基盤におけるMLパイプライン追加の課題と、その課題解決の取り組みについて共有しました。 具体的には、SageMakerの役割の単純化とパイプライン間のコンテナイメージ共通化により、MLパイプライン追加に伴う学習コストと開発工数を大幅削減できた経験をお伝えしました。
今後も、NewsPicks内の多様な経済情報や良質なコンテンツ達が、それらに価値を感じるユーザと出会えるよう、推薦システムの開発・改善に挑戦していきます。 特にMLOpsを担うプロダクトエンジニアとしては、データサイエンティストの「このアルゴリズムを使おう!」を最速かつ安全にプロダクトに本番投入できる基盤を目指していきたいと考えています。
もちろん、本ブログで紹介した方法がすべての環境で最適解とは限りません。チーム構成やプロダクト特性、機械学習活用のフェーズによって、最適なアプローチはケースバイケースでしょう。「すべてのアーキテクチャはトレードオフである」という言葉の通り、利点と欠点は必ず共存します。 もし「自社ではこういうアプローチを取っているよ〜!」や「こういうアプローチもあるよ〜!」という情報や経験談などあれば、ぜひお気軽にコメントやお声がけいただけると嬉しいです! 最後までお読みいただき、ありがとうございました! イベントなどでお会いできた際には、ぜひ気軽に情報交換させてください〜!:)