はじめに
本記事は、 AlphaDrive Advent Calendar 2023 の 12/23 公開分の記事になります。
AlphaDrive CTO/NewsPicks for Business 取締役のアカザワです。
冒頭から余談ですが、CTOとしてAlphaDriveのエンジニア組織を2人から立ち上げて3年、一昨年と昨年は同じUzabaseグループであるNewsPicksのAdvent Calendarに参加させていただいておりましたが、2023年ついにAlphaDriveのチーム単独でAdvent Calendarを実施し埋め切る状態と人数規模になりました!!
嬉しい🎉 めでたい🎉🎉
...と喜びを表明させていただき本題です。本記事は2023年10月10日及び11日にオンライン/オフラインで開催されたAWS主催のSaaS on AWSのDay2内セッション『SaaS 企業CTO のLT 祭りテーマ「開発組織のカルチャー」』で発表したLTを擦...文章に再構成して公開したいと思います。
- はじめに
- AlphaDriveのエンジニア組織が掲げる3つの文化
- 全員SREの状態とは?
- なぜ最初からSRE組織を作らない?
- Next Step !! ~Core SREとTeam SRE~
- まとめ
- 最後に
AlphaDriveのエンジニア組織が掲げる3つの文化
2021年より本格的に立ち上げと拡大を開始したAlphaDriveのエンジニア組織では3つの組織文化を掲げています。
NewsPicksの開発組織と共に掲げる、ユーザーに価値を届けるために、良いと思ったことはなんでもやる文化を表す「全員プロダクト開発エンジニア」、多くの判断はトレードオフではなく、丁寧に理想を実践することを現実解としていく「中長期の合理性のために短期的非合理を歓迎する組織」、そして今回のブログで取り上げる、開発初期にこそ強く掲げた「全員SRE」の3つです。
全員SREの状態とは?
AlphaDriveのエンジニアチームでは現在30名規模で複数のプロダクト(マルチテナント型BtoBSaaS及び自社メディアサービス)を開発しています。 組織の立ち上げ時、決めた事のうちの1つとして組織及び職種としてのSREの設置条件を定義しました。それは、
正社員が20名規模かつ各ストリームアラインドチームが担当サービスのRealibityに責をもち自己完結して継続開発・改善できている状態
です。この状態を満たすまでは組織・職種としてのSREは設置しないという判断です。 なぜ最初にこの条件を定めたかは後半でお伝えしたいのですが、ストーリムアラインドチーム側がSite Realibilityに適切に責を負う状態を認識し実践した結果、現実の戦術実行としては以下のようなツールや技術の活用が拡大しています。
- プロダクト開発エンジニア自身がインフラ及びCI/CDパイプラインをIaC(AWS CDK)で構築
- AWS CDKを用いることでインフラやCI/CDパイプラインの構築もペアプロ/モブプロを実施
- New Relicを用いてサービスのトレースと改善を継続実施(プロダクト開発エンジニアがObservabilityを高めていける状態。NewsPicksのエンジニアチームの活用事例を参考に道半ばです。)
この部分だけにフォーカスしてしまうと、
全員SRE....つまり全員インフラ領域に強い…ってコト!? と解釈されることがあるかもしれません。それはとても重要な要素なのですがあくまで結果状態、目的に至るまでの達成手段であって作りたい文化そのものではありません。
本番環境のオペレーションやSLO・SLIなどの指標通じてSite Reliabilityと継続的改善にプロダクト開発エンジニアが責任を持つ文化を維持・強化していく過程で手段として必然的に各プロダクト開発エンジニアが平均してインフラやCI/CDへの技術的知見が高い組織の状態になっています。

なぜ最初からSRE組織を作らない?
冒頭で示した通り、エンジニア組織の立ち上げ期に意志を持って組織や職種としてのSREを配置しない、という点は組織立ち上げ時に定めた条件でした。
なぜその条件を定めたか、それは過去に所属したエンジニア組織で各プロダクトを担う開発チーム(当時はそう呼称してはいなかったがいわゆるストリームアラインドチームに類する)が自サービスのSite ReliabilityやObservabilityを適切にコントロールできず、また指標としても把握できず、責任を負えない組織状態になってしまったことに起因します。
とても極端に言うと(多少デフォルメしてます)「スミマセン涙...Kubernetesのポッドが立ち上がらないんですけど...」「デプロイがコケたんですが助けてほしいです...」とSREチームのサポート無しではプロダクトを自己完結して継続提供できない状態の組織でした。当然SREチームのメンバーはとてもフォローしてくださっていましたが(それはまるでド◯えもんのような心で「しょうがないな、プロダクト開発チームは〜」といった感じで)、同時に本来的にSREが担うべき戦略領域に時間を割けていないことにフラストレーションを感じていたのも当然理解していました。
(ちょっと表現としてはダークなニュアンスが含まれてしまうかもしれませんが、端的にその状態の危うさをわかってもらうために登壇や説明の場では靴紐を自分で結べないランナーといった表現をすることもあります。)
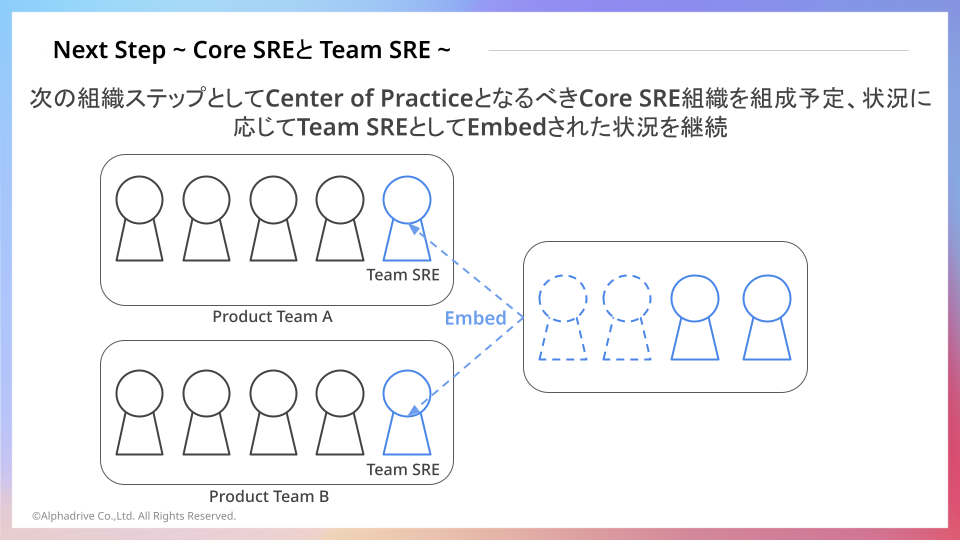
Next Step !! ~Core SREとTeam SRE~
本記事ではSREを配置しない論旨でブログを書いていますが24年、AlphaDriveでは新体制・新組織の構築の1要素として、組織としてのSREの組成を進めています。それは当初定めた組織・職種としてのSREを配置する条件をエンジニア組織全体が満たしたと判断したためです。
余談ですが、私がエンジニア組織をリードしていく際に、常に未来の組織図のパターンを優先順位とともに作成し、部分または全体に対してその組織図に変更するための発動条件も定義しています。発動条件となりえるのは、例えば要職の採用や昇格であったり、例えばサービスのグロースの状況であったり、例えば今回のような定性的ですが組織の文化状態だったりします。)
23年は規模と採用の拡大に応じて、他社ではSRE組織に所属していたエンジニアも複数ジョインしてくださり、また全員SRE文化の浸透と拡大に伴ってAlphaDriveにジョインして以降その領域に強い興味とパフォーマンスを発揮してくれるメンバーも増えました。
つまり、全員SREのスキルと文化の浸透と共に、高いレベルで全員が実行できる状態は維持したまま、本人の強みや特性にあわせて自然発生的にプロダクト内部にSRE領域を担うメンバーの濃淡が発生、結果としてEmbeded SREのような組織状態に遷移していきました。(繰り返しになるが特定メンバーへの依存が高い状態ではありません。)
今のストリームアラインドチームの状態であれば職種や組織としてのSREに過度な依存状態にならない、つまりSREが戦術実行に忙殺されるのではなく、適切に全エンジニアが戦術実行を担える上でSREが戦略を担う存在として組織を牽引できると判断しています。つまり、Center of Practiceを担う組織としてのSRE、です。
こちらも余談ですが、上記のような組織ポリシーと状態は採用時もSRE所属だったエンジニアの皆様からの反応は良く、「わかってるやん!!」とリアクションをいただくことが多いです。やはり大小誰もが戦術実行(かっこよく表現していますが雑多なフォローも含めて...)に負われて本来リードしたい戦略に時間を割けない経験があるためです。

まとめ
SREは組織や職種ではなく方法論・文化・スキル🙌
Core SRE組織への依存度が高い状態になる前に、早期から全員SRE文化を作り上げることでReliabilityの改善にスキルとマインド両面で強い組織になる💪
Core SREへの依存度が高くない組織状態こそ、SRE組織が日々のフォロー業務に追われることなく戦略に集中し、Center of Practiceを実践できる😀(NewsPicksプロダクト組織がUzabaseグループ内での先行事例)
最後に
本ブログで話した立ち上げ期のエンジニア組織ポリシーは択一的な正解を示唆するものでは全くありません。
弊社内でも、インフラ領域(の技術や知見)、DevOpsの思想とSREとしての実装、Platform Engineering等の概念の区分けは行いつつ、自社とプロダクトの特性(規模とフェーズ含む)を考慮して現在の状態にあります。そして自社においては2名->30名規模に拡大する上でこのポリシーと組織構造は大きくプラスに働いた(そしてだからこそ組織として、Center of PracticeとしてのSREを組成できる)と考えています。
これを読んでくださった皆様に、事例の1つとして参考になる部分があれば幸いでございます。