こんにちは。SPEEDA開発チームの鈴木です。
これまでマルチホストでのContainer間通信について、
といった話をしてきましたが、3回目となる今回はこれまでの内容を踏まえた上でKubernetesのネットワークについてお話します。内容としては大きく次の2つになります。
- どうやってマルチホストでのContainer間通信を実現しているか
- Service名でPodと通信できるようするための仕組み
では早速1つ目の話をはじめましょう。Kubernetesを利用する場合、基本的には複数のノード上にKubernetesクラスタを構築することになります。
(minikubeを使って単一ノードからなるKubernetesクラスタを構築するような例外はあります)
つまり何らかの方法でホストをまたいでContainer間通信を行うわけですが、そのための方法は3つあります。
- マルチホストでContainer間通信を行う3つの方法
- 1.自前でOverlayNetworkを構築してKubernetesと連携させる
- 2.CNI(Container Network Interface)を使う
- 3.kubenetを使う
- マルチホストでContainer間通信ができるだけでは解決しない問題
- Service
- Serviceの機能はどのように実現されているか
マルチホストでContainer間通信を行う3つの方法
- 自前でOverlayNetworkを構築し、それをKubernetesと連携させる
- CNI(Container Networking Interface)を使う
- kubenetを使う
それではこれから上記3つについて少し詳しく説明していきます。
1.自前でOverlayNetworkを構築してKubernetesと連携させる
前回説明した flannel のようなツールを用いてOverlayNetworkを構築する方法です。
私が2016年にCoreOSクラスタ上でKubernetesクラスタをマニュアルで構築したとき、CoreOSの公式ドキュメントに記載されていた方法がこれです(CoreOSがContainer Linuxに改名される前の話です)。
ちなみにCoreOSの場合はflannelを用います(flannelはCoreOS社が開発しています)。
この場合、CoreOSのcloud-configにflannelの設定とflannelに合わせたDockerの設定が必要になります。
当然すべてのノードに対して設定が必要になるのでなかなか面倒です。
2.CNI(Container Network Interface)を使う
CNIは、Cloud Native Computing Foundation※のプロジェクトで、
Container内のNetwork Interfaceを構成するためのプラグインを開発するための仕様とライブラリなどから構成されています。
ネットワーク層をプラガブルにしたいという考えは、多くのContainer RuntimeとOrchestration Toolが共通して持っている考えのため、重複を避けるために定義されました。
※Cloud Native Computing Foundationは、Kubernetesの開発主体です。 DockerやCoreOS、Red Hat、Google、IBM、Mesosphere、シスコ、インテルなどが主導して2015年7月に発足しました。
KubernetesはこのCNIプラグインを利用することができます。 ちなみにDocker自体もCNIとは別にネットワークプラグインを利用できる仕組みを持っています。
CNIを利用できるContainer Runtime
公式ページによると現在(2017年9月)CNIを利用できるContainer Runtimeは以下のようなものがあるようです。
Kubernetesだけではなく、MesosなんかもCNIを利用できるみたいですね。
3rd Party Plugins
以下はCNIの仕様に則って作成されたCNIプラグインです(2017年9月現在)。
注意点として、上述したようにCNIはKubernetesのためだけのインタフェースではないので、Kubernetes用ではないプラグインもあることを挙げておきます。
- Project Calico - L3の仮想ネットワーク
- Weave - 仮想ネットワーク
- Contiv Networking - 仮想ネットワーク + 柔軟なネットワークポリシー制御を提供
- SR-IOV
- Cilium - Container用 BPF & XDP
- Infoblox - ContainerのIPアドレスを管理するサービス(IPAM)
- Multus - Kubernetesのマルチプラグインとして動作。複数のプラグインのグループ化(他のプラグインをdelegateして呼び出すらしい)。
- Romana - KubernetesのためのL3の仮想ネットワーク + ネットワークポリシー制御
- CNI-Genie - Kubernetesのマルチプラグインとして動作。一つのContainerに複数のネットワークインタフェースを割り当て、インタフェースごとにCNIプラグインを割り当てられる。例えばeth0はCalico、eth1はFlannel、eth2はWeaveなど。つまりContainerが複数のネットワークにまたがることができる。
- Nuage CNI - Kubernetesのための仮想ネットワーク + ネットワークポリシー制御
- Silk - Cloud Foundryのためのプラグイン。flannelに触発されたらしい。
- Linen - Open vSwitchでOverlayNetworkを構築するプラグイン
これらを見ると、CalicoやWeaveといった単体でContainerの仮想ネットワークを構築できるツールがCNIプラグインとしても提供されていることがわかります。
プラグインの要件を満たすように既存の機能をうまく使っているのでしょうね。
余談ですが、flannelもそうですが、Calico, Weave, Silk, Linenというように「生地」に関連した名前のものが多いですね。
Kubernetesから利用するのは当然Calico, Weave, Contivといった仮想ネットワークのためのCNIプラグインになります。
CNIプラグインの動作
続いてCNIプラグインはどう動作するのか、具体的にどんなものなのかをご理解いただくために、少々ソースコードを読みながら解説します。
CNIプラグインのソースコード
CNIプロジェクトは、CNIプラグインを簡単に開発できるようにスケルトンを用意しています。
プラグインの動作は、このスケルトンと実際にスケルトンを使って作られたプラグインの両方を見ると理解できると思います。
では順番に見ていきましょう。まずスケルトンからです。軽く眺めて次にいきましょう。
(注:抜粋です。コードすべてではありません。またあくまでこれは今現在のバージョンのコードです。)
type CmdArgs struct { ContainerID string Netns string IfName string Args string Path string StdinData []byte } type dispatcher struct { Getenv func(string) string Stdin io.Reader Stdout io.Writer Stderr io.Writer ConfVersionDecoder version.ConfigDecoder VersionReconciler version.Reconciler } func PluginMain(cmdAdd, cmdDel func(_ *CmdArgs) error, versionInfo version.PluginInfo) { if e := PluginMainWithError(cmdAdd, cmdDel, versionInfo); e != nil { if err := e.Print(); err != nil { log.Print("Error writing error JSON to stdout: ", err) } os.Exit(1) } } func PluginMainWithError(cmdAdd, cmdDel func(_ *CmdArgs) error, versionInfo version.PluginInfo) *types.Error { return (&dispatcher{ Getenv: os.Getenv, Stdin: os.Stdin, Stdout: os.Stdout, Stderr: os.Stderr, }).pluginMain(cmdAdd, cmdDel, versionInfo) } func (t *dispatcher) pluginMain(cmdAdd, cmdDel func(_ *CmdArgs) error, versionInfo version.PluginInfo) *types.Error { cmd, cmdArgs, err := t.getCmdArgsFromEnv() if err != nil { return createTypedError(err.Error()) } switch cmd { case "ADD": err = t.checkVersionAndCall(cmdArgs, versionInfo, cmdAdd) case "DEL": err = t.checkVersionAndCall(cmdArgs, versionInfo, cmdDel) case "VERSION": err = versionInfo.Encode(t.Stdout) default: return createTypedError("unknown CNI_COMMAND: %v", cmd) } if err != nil { if e, ok := err.(*types.Error); ok { // don't wrap Error in Error return e } return createTypedError(err.Error()) } return nil }
はい、続いてはスケルトンを利用した実際のプラグインです。
これはCNIプロジェクトがサンプルとして用意している単純なプラグインです。
plugins/plugins/main/loopback/loopback.go
func main() { skel.PluginMain(cmdAdd, cmdDel, version.All) } func cmdAdd(args *skel.CmdArgs) error { args.IfName = "lo" // ignore config, this only works for loopback err := ns.WithNetNSPath(args.Netns, func(_ ns.NetNS) error { link, err := netlink.LinkByName(args.IfName) if err != nil { return err // not tested } err = netlink.LinkSetUp(link) if err != nil { return err // not tested } return nil }) if err != nil { return err // not tested } result := current.Result{} return result.Print() } func cmdDel(args *skel.CmdArgs) error { args.IfName = "lo" // ignore config, this only works for loopback err := ns.WithNetNSPath(args.Netns, func(ns.NetNS) error { link, err := netlink.LinkByName(args.IfName) if err != nil { return err // not tested } err = netlink.LinkSetDown(link) if err != nil { return err // not tested } return nil }) if err != nil { return err // not tested } return nil }
CNIプラグインのソースコード解説
それではいよいよ解説に入ります。このサンプルのmain関数を見てください。CmdArgsを引数にとる関数2つを、スケルトンのPluginMain関数に渡しています。
func main() {
skel.PluginMain(cmdAdd, cmdDel, version.All)
}
このcmdAddとcmdDelはContainerが追加・削除されたタイミングで(CNIプラグインを利用するプログラム)から呼び出される関数です。
引数のCmdArgsは、スケルトンを見ると次のようになっています。
type CmdArgs struct { ContainerID string // ContainerのID Netns string // ネットワーク名前空間名 IfName string // インタフェース名 Args string // プラグイン実行時の引数 Path string // CNIプラグインを検索するパスのリスト(パスは:で区切る) StdinData []byte // 標準入力の値 }
つまり、プラグインはContainerの追加・削除を契機として、上記構造体の情報を元に任意の処理を行います。
ちなみにこのサンプルはContainerの追加時にループバックインタフェースをContainerのネットワーク名前空間内に作成し、Containerの削除時にループバックインタフェースをネットワーク名前空間から削除しています。
CmdArgsについて補足
main関数ではcmdAdd,cmdDelの両方を渡しているが、addとdelのどちらを使うかどう決定されるのでしょう。
これはスケルトンのコードを見ればわかるのですが、CNI_COMMANDという環境変数の値により決定されます。
値がADDの場合cmdAddが呼び出され、値がDELの場合cmdDelが呼び出されます。
またcmdAdd,cmdDelに渡ってくる`CmdArgsの値はどのようにセットされているのでしょうか。
これも環境変数が使われていて、単純に以下の環境変数の値が構造体の対応する変数にセットされています。
| 環境変数 | CmdArgsの変数 |
|---|---|
| CNI_CONTAINERID | ContainerID |
| CNI_NETNS | Netns |
| CNI_IFNAME | IfName |
| CNI_ARGS | Args |
| CNI_PATH | Path |
つまりCNIプラグインの処理を呼び出すプログラムは、予めこれらの環境変数をセットしておく必要があります。
ここまで簡単にコードを見てきましたが、どうでしょう。結構シンプルな仕組みではないでしょうか。
KubernetesでCNIを使うには
KubernetesでCNIを使う場合は、公式ドキュメントに書いてありますが、
kubelet の引数に --network-plugin=cni の指定と、
CNIの設定を配置するディレクトリ--cni-conf-dir(defaultは /etc/cni/net.d)の指定が必要になります。
またCNIプラグイン自体は--cni-bin-dir(defaultは/opt/cni/bin)に存在する必要があります。
例えばCNIプラグインとして、Weaveを使用する場合、このような感じになります。
$ view /etc/cni/net.d/10-weave.conf { "name": "weave", "type": "weave-net", "hairpinMode": true }
$ ls -lat /opt/cni/bin/weave* lrwxrwxrwx 1 root root 18 Aug 10 14:51 weave-ipam -> weave-plugin-1.9.7* lrwxrwxrwx 1 root root 18 Aug 10 14:51 weave-net -> weave-plugin-1.9.7* -rwxr-xr-x 1 root root 9446280 Jun 7 02:37 weave-plugin-1.9.7*
CNIの仕様について更に詳しく
CNIの仕様について更に詳しく知りたい場合は、公式のこちらをご覧ください。
CNIの設定ファイルについての説明なども書いてあります。
3.kubenetを使う
これはGKEでKubernetesクラスタを構築した場合に利用されている方法です。
kubenetが使用されていることは、GKEのクラスタに接続して ps ax | grep kubeletなどとしてkubeletコマンドの引数を見ることで分かります。
$ ps ax | grep kubelet 3461 ? Sl 1218:07 /usr/local/bin/kubelet --api-servers=https://xx.xxx.xxx.xxx --enable-debugging-handlers=true --cloud-provider=gce --pod-manifest-path=/etc/kubernetes/manifests --allow-privileged=True --v=2 --cluster-dns=10.11.240.10 --cluster-domain=cluster.local --cgroup-root=/ --system-cgroups=/system --network-plugin=kubenet # ←ここ --runtime-cgroups=/docker-daemon --kubelet-cgroups=/kubelet --node-labels=beta.kubernetes.io/fluentd-ds-ready=true,cloud.google.com/gkenodepool=default-pool --babysit-daemons=true --eviction-hard=memory.available<100Mi,nodefs.available<10%,nodefs.inodesFree<5% --anonymous-auth=false --authorization-mode=Webhook --client-ca-file=/etc/kubernetes/pki/ca-certificates.crt --feature-gates=ExperimentalCriticalPodAnnotation=true --experimental-allocatable-ignore-eviction
--network-plugin=kubenetという引数が与えられていますね。
ちなみにCNIを使う場合は--network-plugin=cniという指定でした。
kubenetを使用する場合、cbr0という名前のブリッジが作成され、cbr0に接続されたpod用のvethペアも作成されます。
更に言うとkubenetを使用する場合、実はCNIプラグインが使用されているようです(恐らくブリッジへの接続などで)。
例えばGKEの場合、クラスタの/opt/cni/bin配下を見てみると、以下のようなプラグインが配置されています。
/opt/cni/bin$ ls -l -rwxr-xr-x 1 root root 4026452 Mar 22 20:04 bridge -rwxr-xr-x 1 root root 2901956 Mar 22 20:03 cnitool -rwxr-xr-x 1 root root 9636499 Mar 22 20:04 dhcp -rwxr-xr-x 1 root root 2910884 Mar 22 20:03 flannel -rwxr-xr-x 1 root root 3102946 Mar 22 20:04 host-local -rwxr-xr-x 1 root root 3609358 Mar 22 20:04 ipvlan -rwxr-xr-x 1 root root 3170507 Mar 22 20:04 loopback -rwxr-xr-x 1 root root 3640336 Mar 22 20:04 macvlan -rwxr-xr-x 1 root root 2733314 Mar 22 20:04 noop -rwxr-xr-x 1 root root 4000236 Mar 22 20:04 ptp
まとめ
これまでマルチホストでのContainer間通信を実現するための3つの方法を説明してきたわけですが、自前でやるにしろ、CNIプラグインやkubenetを利用するにせよ、Kubernetes本体の機能はほとんど使われていないことがわかったかと思います。
マルチホストでContainer間通信ができるだけでは解決しない問題
前回の記事で私は「Overlay Networkを構築するだけでは、Containerが起動するホストが動的に変わるようなケースには対応できません。」というようなことを書きました。これはどういうことを言っているのか説明しましょう。
まず、KubernetesのようなオーケストレーションツールでContainerを起動する場合、基本的にはDeployするホストをユーザーが直接指定することはありません。Kubernetesがホストの状況(負荷とか空き容量とか)を見て、適切なホストにDeployしてくれるからです。そう、つまりContainerがどこにDeployされるかは予めわからないのです。
もちろんDeploy後であれば、DeployされたホストのIPを知ることができます。しかしContainer間で連携を行う場合、Deployされるまで連携するContainerのIPが分からないのは不便きわまりないです。この問題は、当然、ホストをまたいでContainer同士が通信できても解決しません。
この問題を解決するには、どのホストにContainerがDeployされてもContainerにアクセスする側が気にしなくていいような仕組みが別に必要になります。
KubernetesではServiceがそのための仕組みを提供しています。
Service
Kubernetesをお使いの方はご存知の通り、Serviceはいわゆるロードバランサーで、名前をつけてPod(Kubernetesのリソースの一つでContainerを管理する)と紐付けておくことで、Service経由でPodとやりとりができるようになります。Podがスケールされて複数のホストに存在する場合は、ロードバランシングしてくれたりもします(Kubernetes Cluster上のPodからのみ名前解決できる)。
もう少し具体的に説明しましょう。まず、Serviceを生成するとServiceには自動的にIPが割り当てられます。
そしてこのIP(とServiceで指定したPort)を介してServiceに紐づくPodとやりとりすることができます。そのため、どのホストにPodがDeployされているか気にする必要がなくなります。
ちなみにこのIPは仮想的なIPで、紐づく物理的あるいは仮想的なNICはどこにも存在しません。
またこのIPはKubernetes Cluster上のPodからのみやりとりできます。

しかし何故Podを直接名前解決できるようにせず、Serviceを挟んでいるのでしょうか。
Podのスケールアウトに対応するためでしょうか。でもこれはDNSラウンドロビンで対応できそうですね。
では、仮にPodを直接名前解決できたとしたらどうでしょう。そして、その名前解決の結果がキャッシュされ、キャッシュが有効なうちに何らかの理由でPodがフェールオーバーされて、これまでとは別のホストで起動されたらどうなるでしょうか。困ったことになりますね。このあたりのことは公式のここで言及されています。
さて、ただただServiceの機能について説明するだけでは面白くないので、今回は最後にもう少し突っ込んだ話をしたいと思います。
Serviceの機能はどのように実現されているか
今回は機能を次の2つに絞って「誰」が「どのように」実現しているかを説明します。
- 名前解決
- ルーティング
ルーティングというのは、ServiceのIP(とPort)にアクセスされたら対応するPodのIP(とPort)にフォワードするという意味で書きました。
担当者は誰だ?
まず、こちらをご覧ください。これはKubernetesのアーキテクチャ図で、これを見るとKubernetesが様々な登場人物(Component)から成るツールだということがわかります。「誰」がという表現をしたのはこのためです。
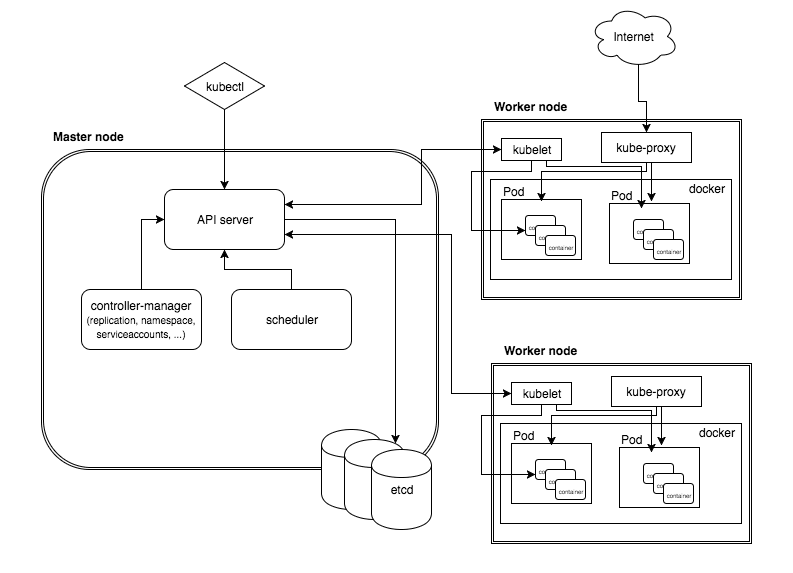
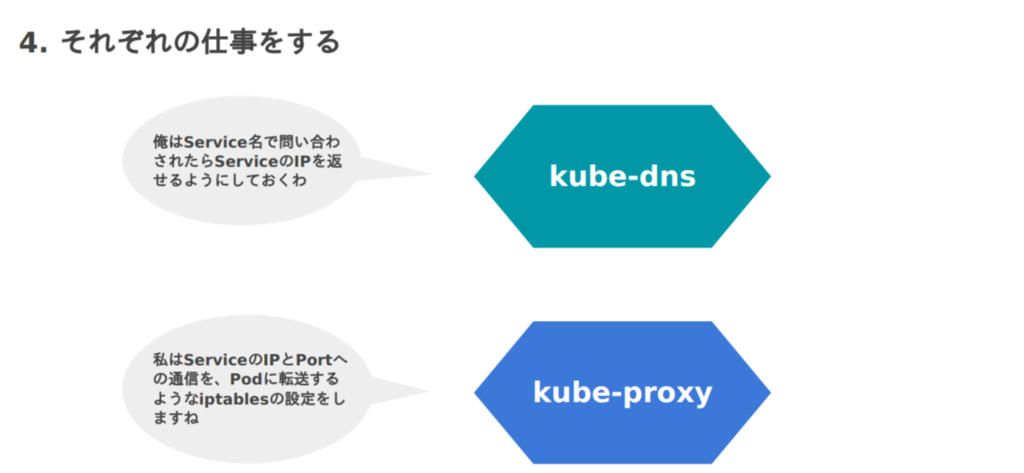
今回の話でいうと、名前解決の部分を担当しているのがkube-dns(上図にはいませんが)で、ルーティングの部分を担当しているのがkube-proxyです。
では、「どのように」それを実現しているのでしょうか。
彼らは一体何をやっているのか?
彼らがやっていることを端的に表すと「ServiceやEndpointリソースを監視して、リソースの状況に合わせたアクションを起こす」ということをやっています(今回はEndpointリソースには言及しません)。
もう少し具体的に説明しましょう。
Kubernetesのkube-apiserverは、自身が管理している各種リソース(ServiceやNode、Pod、Secretなど)について、問い合わせる口を持っています。
そして問い合わせを行った結果、以前の問い合わせの結果との差分から、リソースの「追加」「削除」「更新」といったリソースの変化を検知しイベント通知を行うためのライブラリが用意されています。このライブラリは汎用的に作られていて、「追加」「削除」「更新」のイベント通知を受けた際に処理を行うイベントハンドラを簡単に設定できるようになっています。
kube-dnsやkube-proxyはサーバとして起動され、常駐しながら上記の仕組みを利用してServiceリソースを監視し、状況に応じた処理を行っています。
実際のソースコードを見てみましょう。
次はkube-dnsのパッケージのコードです。
dns.go
func (kd *KubeDNS) setServicesStore() { // Returns a cache.ListWatch that gets all changes to services. kd.servicesStore, kd.serviceController = kcache.NewInformer( kcache.NewListWatchFromClient( kd.kubeClient.Core().RESTClient(), "services", v1.NamespaceAll, fields.Everything()), &v1.Service{}, resyncPeriod, kcache.ResourceEventHandlerFuncs{ AddFunc: kd.newService, DeleteFunc: kd.removeService, UpdateFunc: kd.updateService, }, ) } func (kd *KubeDNS) newService(obj interface{}) { if service, ok := assertIsService(obj); ok { glog.V(3).Infof("New service: %v", service.Name) glog.V(4).Infof("Service details: %v", service) // ExternalName services are a special kind that return CNAME records if service.Spec.Type == v1.ServiceTypeExternalName { kd.newExternalNameService(service) return } // if ClusterIP is not set, a DNS entry should not be created if !v1.IsServiceIPSet(service) { if err := kd.newHeadlessService(service); err != nil { glog.Errorf("Could not create new headless service %v: %v", service.Name, err) } return } if len(service.Spec.Ports) == 0 { glog.Warningf("Service with no ports, this should not have happened: %v", service) } kd.newPortalService(service) } }
ServiceInformerというのが、Serviceリソースの状態を監視し、通知を行ってくれる構造体になります。
このInformerにハンドラを登録している部分が、AddFuncやUpdateFuncなどと書かれている部分です。
続いてkube-proxyのパッケージのコードを見てみましょう。こちらも同じような感じで、Informerにハンドラが登録されています。
func NewServiceConfig(serviceInformer coreinformers.ServiceInformer, resyncPeriod time.Duration) *ServiceConfig { serviceInformer.Informer().AddEventHandlerWithResyncPeriod( cache.ResourceEventHandlerFuncs{ AddFunc: result.handleAddService, UpdateFunc: result.handleUpdateService, DeleteFunc: result.handleDeleteService, }, resyncPeriod, ) } func (c *ServiceConfig) handleAddService(obj interface{}) { service, ok := obj.(*api.Service) if !ok { utilruntime.HandleError(fmt.Errorf("unexpected object type: %v", obj)) return } for i := range c.eventHandlers { glog.V(4).Infof("Calling handler.OnServiceAdd") c.eventHandlers[i].OnServiceAdd(service) } }
kube-dnsのイベントハンドラは何をしているか
まずkube-dnsのserverの起動部分を見ると分かるのですが、SkyDNSというDNSサービスを起動しています。
func (server *KubeDNSServer) Run() { pflag.VisitAll(func(flag *pflag.Flag) { glog.V(0).Infof("FLAG: --%s=%q", flag.Name, flag.Value) }) setupSignalHandlers() server.startSkyDNSServer() // ここ server.kd.Start() server.setupHandlers() glog.V(0).Infof("Status HTTP port %v", server.healthzPort) if server.nameServers != "" { glog.V(0).Infof("Upstream nameservers: %s", server.nameServers) } glog.Fatal(http.ListenAndServe(fmt.Sprintf(":%d", server.healthzPort), nil)) }
SkyDNSのサーバーには、問い合わせを受けたときに呼び出される「DNSレコードを返す処理」を渡せるようになっており、その部分のみkube-dnsが実装しています。
そしてそのレコードの登録処理が、Serviceの変更の通知を受け取ったときに呼び出される処理なのです。
これによりKubernetes Cluster内で名前解決が可能になります。
kube-proxyのイベントハンドラは何をしているか
まず先に言ってしまうと、ServiceからPodへのルーティングは、iptablesによって行われています。
iptablesの内容を表示させてみると次のようになっています(説明に必要なものだけ抜粋しています)。これはkubernetes-dashboardのルーティングなのですが、Serviceの 10.110.169.150:80 が Pod の 10.42.0.0:9090 にフォワードされていることが分かると思います。
-A KUBE-SEP-4 -s 10.42.0.0/32 -m comment --comment "kube-system/kubernetes-dashboard:" -j KUBE-MARK-MASQ -A KUBE-SEP-4 -p tcp -m comment --comment "kube-system/kubernetes-dashboard:" -m tcp -j DNAT --to-destination 10.42.0.0:9090 -A KUBE-SERVICES -d 10.110.169.150/32 -p tcp -m comment --comment "kube-system/kubernetes-dashboard: cluster IP" -m tcp --dport 80 -j KUBE-SVC-DASH -A KUBE-SVC-DASH -m comment --comment "kube-system/kubernetes-dashboard:" -j KUBE-SEP-4
ちなみにこのdashboardをスケールアウトさせてみると
$ kubectl scale deploy kubernetes-dashboard -n kube-system --replicas=3
このようになります。
-A KUBE-SEP-3 -s 10.44.0.1/32 -m comment --comment "kube-system/kubernetes-dashboard:" -j KUBE-MARK-MASQ -A KUBE-SEP-3 -p tcp -m comment --comment "kube-system/kubernetes-dashboard:" -m tcp -j DNAT --to-destination 10.44.0.1:9090 -A KUBE-SEP-1 -s 10.42.0.0/32 -m comment --comment "kube-system/kubernetes-dashboard:" -j KUBE-MARK-MASQ -A KUBE-SEP-1 -p tcp -m comment --comment "kube-system/kubernetes-dashboard:" -m tcp -j DNAT --to-destination 10.42.0.0:9090 -A KUBE-SEP-2 -s 10.42.0.1/32 -m comment --comment "kube-system/kubernetes-dashboard:" -j KUBE-MARK-MASQ -A KUBE-SEP-2 -p tcp -m comment --comment "kube-system/kubernetes-dashboard:" -m tcp -j DNAT --to-destination 10.42.0.1:9090 # -m statisitc でランダムに宛先を変えている # 1/3の確率で KUBE-SEP-1 -A KUBE-SVC-XGLOHA7QRQ3V22RZ -m comment --comment "kube-system/kubernetes-dashboard:" -m statistic --mode random --probability 0.33332999982 -j KUBE-SEP-1 # 1/2の確率で KUBE-SEP-2 -A KUBE-SVC-XGLOHA7QRQ3V22RZ -m comment --comment "kube-system/kubernetes-dashboard:" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-2 # 残りは KUBE-SEP-3 -A KUBE-SVC-XGLOHA7QRQ3V22RZ -m comment --comment "kube-system/kubernetes-dashboard:" -j KUBE-SEP-3
もう分かったかと思いますが、kube-proxyのイベントハンドラがやっているのは、このiptablesの動的な更新です。 これは上記のkube-proxyのコードを追っていくと分かります(興味がありましたらproxier.goのsyncProxyRulesのあたりをご覧ください)。
まとめ
kube-dnsとkube-proxyがServiceを監視しており、Serviceが作成されたとき、kube-dnsによりDNSレコードが登録され名前解決が可能になり、そしてkube-proxyによりiptablesを使ったルーティングが設定されることが分かったかと思います。
図にするとこのような流れになるでしょうか。
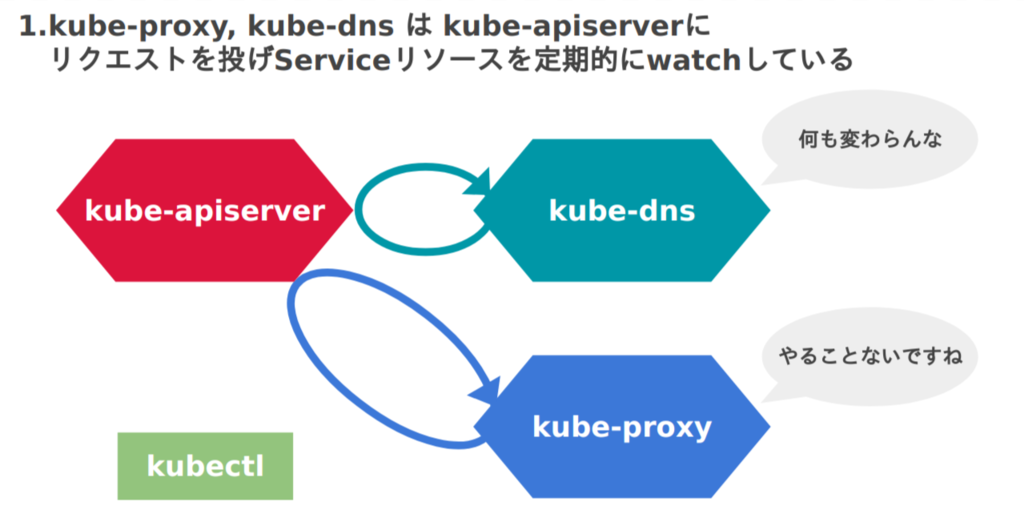
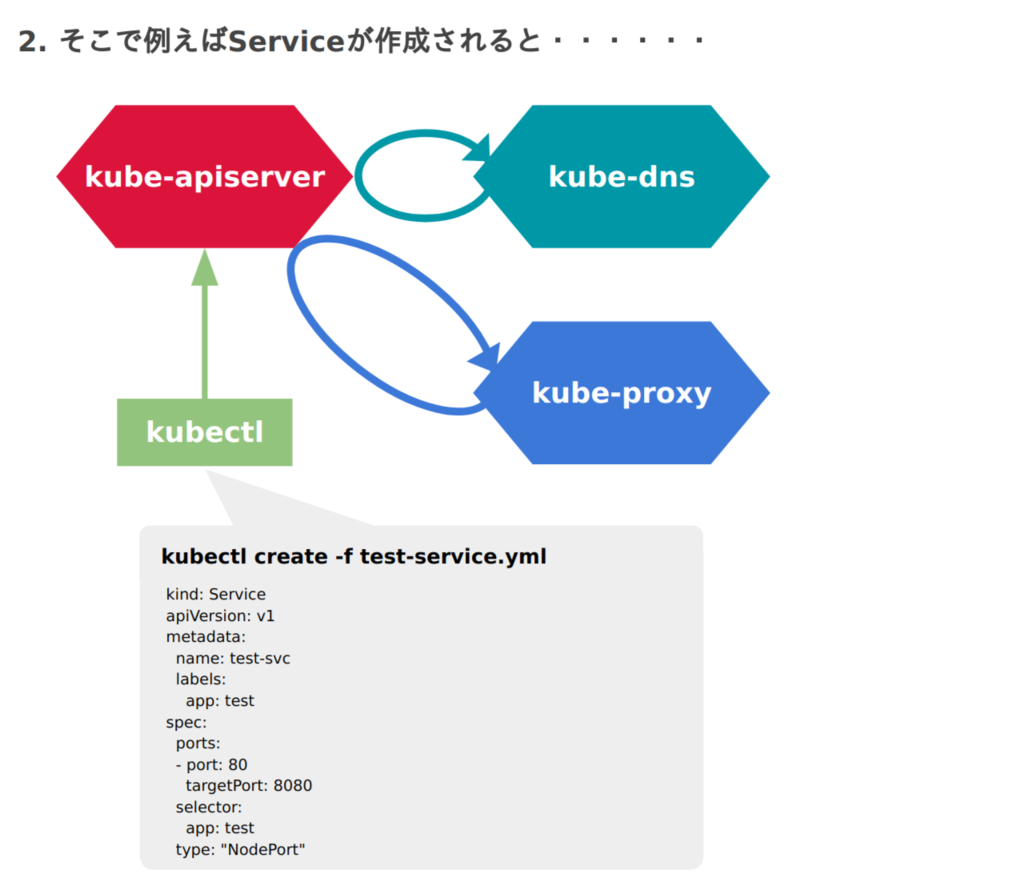
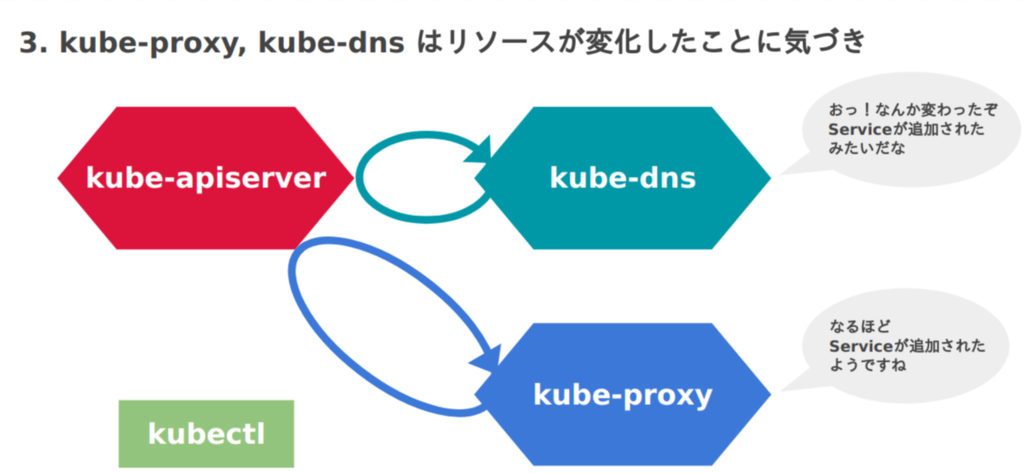

さて、大分長くなりましたがKubernetesのネットワーク話はいかがだったでしょうか。
様々な仕組みは用意しつつ、巧みに自前での実装を回避しているという印象を私は受けました。
Kubernetesは調べていくと感心させられることが多いですね。
シリーズ
第1回: マルチホストでのDocker Container間通信 第1回: Dockerネットワークの基礎
第2回: マルチホストでのDocker Container間通信 第2回: Port Forwarding と Overlay Network
第3回: マルチホストでのDocker Container間通信 第3回: Kubernetesのネットワーク(CNI, kube-proxy, kube-dns) (当記事)