NewsPicks SREチームのEdwin Wilsonです。
NewsPicksでは開発環境のテストデータのプロビジョニングを行うツールとしてDatarefreshというものがあります。 このツールは本番環境のデータストアから開発環境のデータストアに対してデータを同期するアプリケーションです。 対象のデータストアは以下となります。
- Amazon RDS
- Amazon DynamoDB
- Amazon S3
- Amazon ElastiCache
個人情報はRDSにのみに存在しており、マスク処理を行った後、同期しています。 DynamoDB ,S3, ElastiCacheには個人情報を存在しないため、開発に必要なデータをそのまま同期しています。
Datarefreshの実行は開発者がいつでもChatopsで行えます。

Chatopsで呼び出しすると対象データストアが同期されます。

今回のブログではAmazon DynamoDBのデータを同期する為に、これまではAWS Data Pipelineを使っていましたがAWS Backupに変更したという話をします。
- 今までAWS Data Pipelineを利用していた
- AWS Data Pipelineの利用をやめた理由
- Data Pipelineを利用せずにDynamoDBテーブルをエクスポートして、インポートする二つの方法
- DynamoDBのエクスポート/インポート機能を利用した実装
- AWS Backupを利用した実装
- AWS BackupとS3へのエクスポート/インポート機能どれを選ぶのか?
- 機能比較
- Datarefreshではコストの比較
- 結論
今までAWS Data Pipelineを利用していた
今まで、本番と開発環境のDynamoDBデータの同期をする為にAWS Data Pipelineを使ってきました。 以下の図の通り、本番環境のDynamoDBテーブルのデータがS3にエクスポートされて、別アカウントにある開発環境のテーブルにインポートされるようになっていました。

AWS Data Pipelineの利用をやめた理由
- 記事を書いている時点でAWS Data Pipelineはメンテナンスモードに入り、2023年02月28日からコンソールアクセスができなくなっています。
- AWSのコスト抑える為に、開発環境のDynamoDBのキャパシティーの設定を低く設定しており、大量データのインポートをする時に、キャパシティーを増やし、処理が終わったらキャパシティーを減らす事をという処理が必要があります。DynamoDBテーブルのプロビジョンド キャパシティ変更APIは呼び出し数の制限があり、一日で何度もDatarefreshを実行する事でその制限に引っかかる事が何回かありました。
プロビジョニングされたスループットの減少 UpdateTable オペレーションのすべてのテーブルとグローバルセカンダリインデックスでは、ReadCapacityUnits か WriteCapacityUnits (またはその両方) を減らすことができます。新しい設定は、UpdateTable オペレーションが完了するまでは有効になりません。 1 日あたりの DynamoDB テーブルで実行できるプロビジョンドキャパシティーの減少数には、デフォルトのクォータがあります。日付は、協定世界時 (UTC) に従って定義されます。特定の日に、その日に他の減少をまだ実行していない限り、1 時間以内に最大 4 回の減少を実行することから始めることができます。その後、前の 1 時間に減少がない限り、1 時間あたり 1 回追加で減少を実行できます。これにより、1 日で減らすことができる最大の回数は 27 回になります (1 日の中で最初の 1 時間は 4 回、その後は 1 時間ごとに 1 回)。
Data Pipelineを利用せずにDynamoDBテーブルをエクスポートして、インポートする二つの方法
DynamoDBのエクスポート/インポート機能とBackupを使った二つのテーブルの同期方法を紹介していきます。 「Datarefresh」は複数のStep Functionsを組み立てて作っているので、Step Functionsで実装をしてみました。
DynamoDBのエクスポート/インポート機能を利用した実装
AWSのドキュメントによって、
DynamoDB テーブルのエクスポートを使用すると、Amazon DynamoDB テーブルのデータをポイントインタイムリカバリウィンドウ内の任意の時点から Amazon S3 バケットにエクスポートできます。DynamoDB テーブルを S3 バケットにエクスポートすると、Athena、AWS Glue、Lake Formation などの他の AWS サービスを使用して、データの分析や複雑なクエリを有効にできます。DynamoDB テーブルのエクスポートは、DynamoDB テーブルを大規模にエクスポートするための完全マネージド型ソリューションであり、テーブルスキャンに関連する他の方法よりもはるかに高速です。
データを DynamoDB にインポートするには、データが CSV、DynamoDB JSON、または Amazon Ion 形式で Amazon S3 バケット内にある必要があります。データは ZSTD または GZIP 形式で圧縮することも、非圧縮形式で直接インポートすることもできます。ソースデータは、単一の Amazon S3 オブジェクトでも、同じプレフィックスを使用する複数の Amazon S3 オブジェクトでもかまいません。
本番環境でDynamoDBからデータのエクスポートを行うStep Functions
最新のデータが常に開発環境に取り込める状態にするように、本番テーブルのエクスポートは1日に一回実行するようにしています。 Amazon EventBridgeのルールを利用して、1日に1回以下のStep Functionsをキックします。 本番アカウントにあるバケットにデータを保存します。
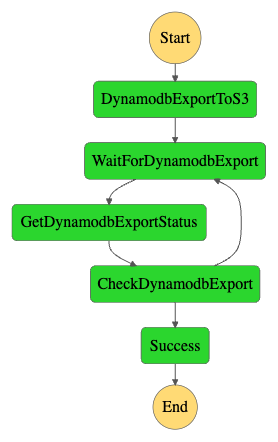
- DynamoDBのデータをS3へのエクスポートを開始する
- エクスポートの終了を待つ
開発環境でDynamoDBのインポートを行うStep Functions
利用者がチャットボットにメッセージを送るタイミングでこのStep Functionsが実行されます。 このStep Functionsが開発用アカウントで実行されて、インポートされるデータが本番のバケットに保存されているので、クロスアカウントオブジェクトコピーができるように適切な権限を付与する必要があります。

- 旧DynamoDBテーブルを削除する
- 旧DynamoDBテーブルの削除完了を待つ
- DynamoDbStreamsを有効化する
- タグを付ける
DynamoDBエクスポート機能でエクスポートされたテーブルは、テーブルのメタデータや、インデックス情報などがエクスポートされないので、DynamoDBインポートを呼び出しする時、テーブルの作成パラメーターを全て渡す必要があります。
例)
{
destinationTableName: `dev-3-Following`,
streamSpecification: {
streamViewType: "NEW_AND_OLD_IMAGES",
},
tableCreationParameters: {
AttributeDefinitions: [
{
AttributeName: "index",
AttributeType: "N",
},
{
AttributeName: "user",
AttributeType: "N",
},
],
BillingMode: "PROVISIONED",
KeySchema: [
{
AttributeName: "user",
KeyType: "HASH",
},
{
AttributeName: "index",
KeyType: "RANGE",
},
],
ProvisionedThroughput: {
ReadCapacityUnits: 10,
WriteCapacityUnits: 10,
},
},
},
DynamoDBStreamsを使っている場合は、テーブルの作成パラメーターとして渡す方法がない為、テーブルの復元が終わってから有効化する必要があります。
以前説明した通り、DynamoDBのS3へのエクスポートを利用する場合はテーブルのメタデータや、インデックス情報がエクスポートされず、DynamoDBをS3からインポートするタイミングでテーブル作成パラメーターの全て渡す必要があります。 しかし、この記事を書いているタイミングでローカルセカンダリインデックス(LSI)はが付いているテーブルの作成はDynamoDBのインポート機能は対応していません。 DynamoDBインポートにテーブルの作成引数として渡す方法がなくて、LSIはテーブルが作成された以降は付ける事が不可能なので、DynamoDBのエクスポート/インポート機能でLSIが付いているテーブルの管理が不可能です。
AWS Backupを利用した実装
AWS Backupを使う場合は、バックアップボールトという"バックアップを保存および整理するためのコンテナ"にテーブルメタデータを含めてテーブルのバックアップが保存され、そのバックアップから新しいDynamoDBテーブルの作成ができます。 GSIかLSIが元のテーブルに付いている場合は、バックアップボールトから復元されるテーブルも付きます。
本番DynamoDBから開発アカウントのバックアップボールトの保存を行うStep Functions
DynamoDBのS3へのエクスポートと同じく毎日実行します。

S3みたいに、開発アカウントから本番アカウントのバケットを直接読み込みする権限を不要する事はBackupボールトの場合ではできません。 本番アカウントのボールトでテーブルのバックアップができたら、BackupのAPIを使って開発アカウントのボールトにバクアップをコピーする方式になります。
- 本番アカウントのバックアップボールトでテーブルのバックアップの作成を開始する
- バクアップ作成の完了を待つ
- 開発アカウントのバックアップボールトにコピーする
- コピーの完了を待つ
開発環境でAWS BackupのボールトからDynamoDBテーブルの復元を行うStep Functions

- 旧DynamoDBテーブルを削除する
- 旧DynamoDBテーブルの削除完了を待つ
- バックアップボールトからDynamoDBテーブルを作成する
- DynamoDbStreamsを有効化する
- タグを付ける
AWS BackupとS3へのエクスポート/インポート機能どれを選ぶのか?
機能比較
| サービス | テーブルメタデータの保存 | LSI対応 | DynamoDB Streams対応 |
|---|---|---|---|
| DynamoDBのS3へのエクスポート/インポート | エクスポート時にテーブルのメタデータが保存されないので、S3からの復元の時に改めてテーブルの作成時に必要な引数を全部渡す必要がある。 | LSIをが付いているテーブルの作成ができない。 | バックアップからの復元後に作成する。 |
| AWS Backup | テーブルのメタデータがエクスポートされ、テーブルの復元時に決めなくても大丈夫 | エクスポート時にテーブルにLSIをが付いている場合は、復元されるテーブルもLSIが付く。 | バックアップからの復元後に作成する。 |
Datarefreshではコストの比較
| サービス | エクスポート($/GB) | インポート($/GB) | ストレージ($/GB/月) |
|---|---|---|---|
| DynamoDBのS3へエクスポート/インポート | 0.171 | 0.114 | 0.024 |
| AWS Backup | 0 | 0.171 | 0.114 |
エクスポート処理は1日に1回に実行し、インポート処理の実行は多くても1ヶ月で数回かしか実行されます。 月にエクスポート30回とインポート10回をベースで計算すると、DynamoDBエクスポートはBackupの3.4倍の費用がかかる事がわかります。
エクスポート月30回とインポート~90回からBackupの方が高くなりますが、DatarefreshではDynamoDBのS3へエクスポート/インポートの方がコスパいいです。
結論
AWS Backupの方は使い方がシンプルで対応できるケースが多いです。コストは場合によって変わるのでケースバイケースでどれぐらいかかるか計算する必要があります。 Datarefreshの場合はLSI対応が必要なテーブルだけをBackupを使う予定でしたが、月30回程度のエクスポート、インポートは10回ぐらいの場合Backupの方がコスパがいいので、全テーブルをBackupで対応する事に決まりました。