はじめに
みなさん、こんにちは!SaaS事業 Product Team の成です。
本日はSWEの経験しかない私が機械学習の開発仕事をやってみて学んだことや感想をシェアしたいと思います。機械学習の観点から見ると入門レベルの内容ですが、よろしくお願いします。
きっかけ
簡単な自己紹介をさせていただきます。エンジニア経歴は約17年、UBにジョインする前では、SI業界やスマホアプリなどの開発経験を積んできて、8年前UBにジョインしました。UBでも主に自社SaaS事業の各プロダクトの開発をやっています。Product Team(SWE、MLE、SRE、TestEngineerをまとめるエンジニアチームです)ではマイクロフロントエンド・マイクロサービスを推進しており、そのお陰で色な開発言語や技術を触れることができましたが、機械学習の開発経験はまだありませんでした。
Product Teamでは各プロジェクトの開発チームはエンジニア4~5人(職種を跨る場合もある)で、XPというアジャイル手法を徹底的に実施し(日々ペアプロやTDDなどのプラクティスをやっている)、開発を進めています。そして、3ヶ月1回チームシャフルを行い、自分が行ってみたいチームが行けるチャンスがあります。皆さんのWillが優先に考えられますが、場合によっては微調整も行われます。2024の年始から全く機械学習開発の経験がない私がその微調整のお陰で、MLEの方3名と4人チームを組んで開発することになりました。
何を開発しているか
プロジェクトは2023年の終わり頃始まったので、私は途中参加の形でジョインしました。開発内容は弊社SaaSプロダクトで扱っている企業の概要説明を読み込んで特定なタグを自動的に付与する仕組みを開発することです。すなわち、企業にタグを紐づける分類問題を解決するモデルを開発しています。
最初の2~3ヶ月はまだSWEに近い開発で、主に企業概要を企業APIによって取得したりタグの説明文も別のAPIによって取得し整形したり、パイプラインなどの開発(すなわち、機械学習の前処理の部分)がメインでしたので、以前の開発作業とそんなに大きい差異はなかったですが、3月後半からモデルの訓練、推論や評価など機械学習的な開発段階に入ると知識のギャップを感じてしまい、段々議論のときも発言が少なくなってしまいました。
機械学習の門外漢
常にペアプロしているし、チームのMLEの皆さんも優しいので、何か分からないことがあれば随時質問していますが、機械学習知識の土台がない私にとってはピンポイント的な回答は場合によって理解に時間が掛かるし、なかなか定着もできなかったです。もともとはコードを書きながらいつの間に理解できるっしょと思いましたが、ちゃんと機械学習の基礎から学ばないと行けないなと感じてMLEの皆さんに相談したら、「ゼロから作るDeep Learning」という本が推奨されました。
4月から2ヶ月をかけて完読しました。「モデルってなに?」、「ロス関数ってなに?」、「なんで教師データで訓練したら精度が高くなるか?」などの疑問は解消できて機械学習のイメージも段々見えてきました。ここで自分の理解を整理してまとめておきます。もし参考になれれば幸いです。
機械学習とは
「人工知能」、「機械学習」、「ニューラルネットワーク」、「深層学習」などの単語はよく聞くと思いますが、それぞれどんな関係かも分からなかったのは昔の自分です。ネットで調べたり、本を読んだりして下記の図にまとめてみました。

ニューラルネットワークとは
「ゼロから作るDeep Learning」は主にニューラルネットワークの訓練や評価についてPythonコード経由で説明してくれました。ニューラルネットワークを一言で言ってみると人間の脳内の神経細胞同士の繋がりを再現した数理モデルだと考えられます。
パーセプトロン

ニューロン といいます。x1, x2は入力値、w1, w2は重みパラメータであり、yは出力値で、その計算式は y=x1・w1+x2・w2 になります。そしてその計算結果をある関数に挟んで非線形にします。ニューロンや階層を増やせばより複雑なニューラルネットワーク構成になります。
活性化関数
線形関数というのは、例えば y=2x+10 という式があります。図のようにyとxの関係が一直線になります。なぜ非線形化が必要なのかは同じチームのMLEの方から「活性化関数を使わない場合は線形変換をいくつ重ねても線形にしか変化しないので、多層にしてもあんまり意味がないから活性化関数を入れて非線形化することでモデルの表現力を向上することができます。」と説明していただきました。

y=f(x)=1/(1+e^(-x)) になります。図のようにxがどんな値でも、yは必ず(0, 1)の区間になります。xが大きければ大きほどyが1に近づけていくし、xが小さければ小さいほどyが0に近づけていきます。ちなみに、eはネイピア数といい、値は「2.7182818・・・」の無限非循環小数になります。

a=x1・w1+x2・w2、シグモイド関数で計算してy=1/(1+e^(-a)) パーセプトロンの出力値として出すことになります。その計算を詳細まで書くと下記のような図になります。

ニューラルネットワークの推論
それでは1階層を増やしてより複雑なニューラルネットワークを見てみましょう。まずはここで新しい人物が登場します。バイアスです。図の中に灰色のニューロンの値は常に1であり、それを掛け算しているb・・・はバイアスです。ニューラルネットワークにあるパラメータは主に重みパラメータ(w・・・)とバイアス(b・・・)この2種類です。そして入力値の数や中間層の層数を増えればそのパラメータの数もどんどん増えていきます。ChatGPTのようなLLMのパラメータが数億や数十億と言っている数は主にそのパラメータの数のことです。

配列の内積
中間層の計算式は全部図に書いてありますが、パット見煩雑だなという印象かもしれないですが、それを配列の掛け算(内積)として考えてみると分かりやすくなると思います。ちなみにw・・(1)やb・・(1)の括弧にある数字は層を表しています。w・・(1)は1層目を計算するために使っている重みパラメータで、w・・(2)は2層目(出力層)を計算するためのものです。
それでは、中間第1層の計算を例にして説明します。x1, x2, x3は1元配列で考えると x=[x1, x2, x3] になります。配列の形を (行数, 列数) で表すと x(1, 3) になります。重みパラメータwは(w11〜w34)があるので、2元配列で考えてみます。 w=[[w11, w12, w13, w14], [w21, w22, w23, w24], [w31, w32, w33, w34]] その形は w(3, 4) になります。バイアスは b=[b1, b2, b3, b4] になります。1元配列のxと2元配列のwの内積は下記の図で考えられます。

x(2, 3)・w(3, 4)=y(2, 4) になります。内積の 左配列の列数 と 右配列の行数 は必ず同じでないといけないので、xとwを逆で内積するとw(3, 4)・x(2, 3) 計算できなくなります。
その配列計算のお陰で、ニューラルネットワークの構成は柔軟に調整できます。つまり、中間層にあるニューロンの数はwの列数で決まります。中間第1層のように広がっていきたければwの列数を増やせばよいし、最後の出力を2値結果(例のz1'とz2')にしたければ、中間第2層のwの列数を2にすればよいです。2値結果は2値分類問題であり、例えばyesかnoかを答えてほしい場合などです。
※分類問題とは、いくつ選択肢の中で一つまたは複数を選択することです。正解が一つの場合はマルチクラス分類と言います。例えば、yesかnoのどっちが正解である問題です。正解が複数の場合はマルチラベル分類と言います。例えば、この記事はどんなタグを付けるか的な問題です。
numpy
ちなみに、Pythonがよく機械学習のプログラミングに使われる理由の一つはこういう配列計算は便利なライブラリー(numpyナムパイと言う)があるからです。
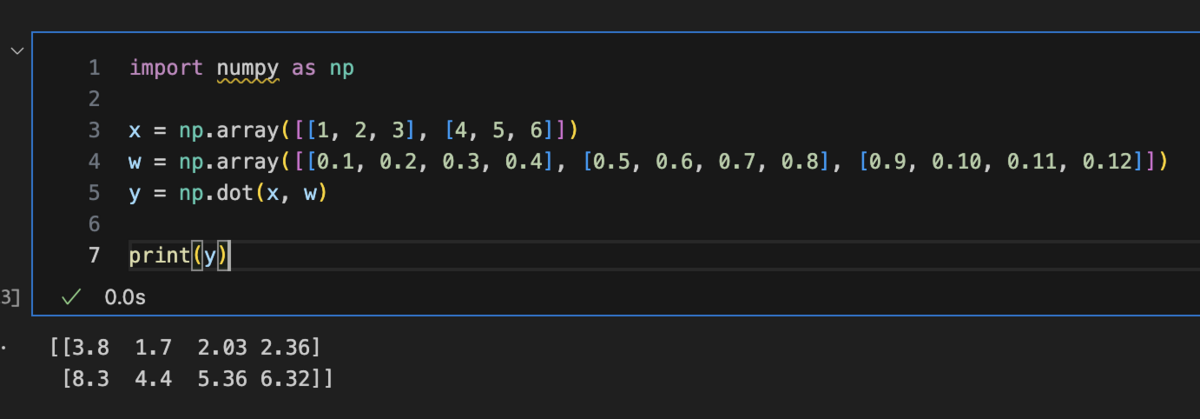

w(3, 4)・x(1, 4)=y(1, 3) という計算はできます。興味があればnumpyで書いてみてください。
推論
上記の方法で層ごとの計算を渡って、z1’, z2’の値は計算されます。分類問題は最終的にパーセンテージで表すことが多いです。Softmax関数で各結果の確率を計算します。例えば、z1'の確率は e^z1 / (e^z1 + e^z2) になり、z2'は e^z2 / (e^z1 + e^z2) になります。つまりz1=2でz2=1の場合は、z1'の確率は73.11%でz2の確率は26.89%になります。
では、入力値や重みパラメータまたはバイアスの初期値はどうやって決めるでしょうか。入力値は色んな形式のデータから数値の配列にすることは特徴量抽出と言います。例えば「明日は雨が降りますか」のような文字列を何らかの方法(例えば各文字のユニコードを取る)で1元配列にしたり、画像の場合はそのまま縦横のピクセル分の2元配列にしたりします。当然なことですが、入力値はかなりモデルの推論結果に影響するため、特徴量抽出は機械学習エンジニアが腕を見せるところの一つです。重みパラメータの初期設定は「Xavierの初期値」という機械学習フレームワークで標準的に使われる初期値設定方法があります。詳細は「ゼロから作るDeep Learning」をご参照ください。
※画像は実際縦横の以外にchannelという軸があり、3元配列ですが、wもchannel文の2元配列を良いすれば計算できます。
上記のように入力値を決め、重みパラメータwと内積しバイアスbを足し算して、活性化関数で収束して、その処理を層ごとで繰り返し、最後の結果をSoftmax関数でパーセンテージで表していく。その一連の処理は推論と言います。プログラムではよくforward()という関数で表します。層の階数や最後の結果の数などを自分で決めれば自作のニューラルネットワークが作れます。
ニューラルネットワークの訓練
モデルの訓練やモデルの学習はよく聞くかもしれないですが、実質は同じことを表しています。それは重みパラメータwとバイアスbを最適に調整することです。wとbは初期値を決めてからずっと変わらないではなく、推論の結果を教師データの正解に近づいていくために何らかの方法でちょっとずつ変更していきます。
ロス関数
正解に近づいていくためには、まずは正解との差はどのぐらいあるかという計算が必要です。それを計算するのはロス関数(loss function)と言います。分類問題のロス関数は交差エントロピー誤差(cross entropy error)がよく使われます。それは推論結果と正解の差の対数を計算することになります。例えばyesかnoの正解データ t: [t1, t2] => t: [0, 1] (t1がyesで、t2がnoです。0が不正解で1が正解とします)があります。推論結果 z': [z1', z2'] => z': [0.7311, 0.2689] (z1'がyesで、z2'がnoです)とします。交差エントロピー誤差の計算式が E = -[t1・log(z1') + t2・log(z2')] になります。t1が0なので、実質は正解の要素だけ計算されます。正解との差は E = -t2・log(z2') => E = -1・log0.2689 => E ≒ 0.5704 になります。もし正解がyesの場合、E ≒ 0.1360 になります。
つまり下記の図と合わせてみると、推論結果zは各分類の確率のため最大1で、推論結果が1に近づけば近づけるほど正解との差が小さくなる。
※ 対数と指数の互換性: y=log(x) <=> x=e^y

E ≒ 0.5704 であることが分かりました。その差を縮ませるためにwとbを少しずつ変えていきます。wとbはそれぞれ配列だし、階層が増えればその数が更に増えていきます。具体的にどの値はどう変えるべきかは直感的で判断は不可能です。そこで微分という数学の知識が必要になります。
微分
微分とは、ある瞬間の変化の量を表したものです。例えば、y=f(x)=2x+10 とうxとyの関数があります。xを極めて小さい数値hの2倍で変更させたら(x+hとx-h)、yはどのぐらい変わるかを計算するのは微分(dy/dx)です。dy/dx=[df(x+h)-df(x-h)]/2h という全微分式になります。その計算は下記の図にまとめました。

y=2x+10 が一直線になり、xがどう変更しても、yの変更量が一定になるという解釈になります。
もしyとxの2乗を関係する場合、例えば y=f(x)=2x^2+10 の全微分(dy/dx)は dy/dx=4x になり、xとの一直線の関係になります。

放物線と任意点の接線 という関係になります。

誤差逆伝播法
一つ層の推論はどんな計算が必要なのかを復習しましょう。
- 入力値(xまたは前の層の出力値)と重みパラメータwを内積する。
A = x・w - 1の結果をバイアスbと足し算する。
B = A + b - 2の結果をシグモイド関数で計算して非線形化にする。
C = 1/(1+e^(-B))
計算図で表すと下記のようになります。計算しやすくするために、入力値x: [3, -1]、重みパラメータw: [1, -2]、バイアスb: -2とします。

- シグモイド関数へ逆伝播してきた微分値は1とする。
- シグモイド関数の全微分(dC/dB)を求めて、それを1の微分値と掛け算する。
dC/dB = C・(1 - C) - バイアスbの足し算を偏微分(dB/db)を求めて、それを2の全微分と掛け算する。
dB/db = 1 - 重みパラメータwの内積の偏微分(dA/dw)を求めて、それを3の偏微分と掛け算する。
dA/dw = x

その中にシグモイド関数の微分(dC/dB)の求め方は、本でもネットでもあんまり詳しく書いているところは見当たらなかったので、自分の理解で解いてみました。原理は上で書いたことと同じく dC/dB=[df(B+h)-df(B-h)]/2h Bの微小変更量に対して関数全体の変更量を計算することです。




偏微分(dB/db)と偏微分(dA/dw)は比較的に簡単で y=2x+10 の全微分を求めたときと同じなので省略します。
※微分する変数が一つの場合は全微分と言い、2つ以上の場合は偏微分になります。例えば、式 A = x・w に対して、(dA/dw)と(dA/dx)はそれぞれ偏微分です。
全体的な処理イメージ
層ごとに誤差逆伝播法を使って、ロス関数で分かった正解との差を各重みパラメータwとバイアスbの変更量を計算して適用して、再度推論から繰り返すことは訓練の全体的な処理イメージです。

最後に教師データ(正解データ)の使い方について紹介します。教師データは一般的に3つ(train, dev, test)に分けて使います。お互いに重複データがないように抽出するし、できれば全ラベルがいい感じに分散している形で分割します。train dataは訓練に使わせて、一度train dataを全部使いまわし終わったら1 epoch(エポック)と言います。訓練は複数epochを回すこともあります。同じく評価ですがdevとtestに分ける理由はdev dataで評価した結果はエラー分析に使えるが、test dataの評価結果はエラー分析に使ってはいけないことです。エラー分析とは、その評価結果をみて入力データの特徴量抽出の改善や、訓練のepoch調整、モデル変更などいろいろ改善施策を考えることです。ただこういう改善はあくまで教師データの範囲で行っているので、やりすぎると過学習になってしまい、dev dataの推論性能がめっちゃ良いですが、他のデータの推論性能がそんなによろしくないかもしれないです。それを防いでモデルの本当の性能を確認するためにはtest dataを使った汎化性能評価が必要です。そのため、test dataはエラー分析には使ってはいけないです。
評価の内容については分類問題によく使われる混同行列やその上で出している適合率、再現率、Fスコア、マクロ平均、マイクロ平均など、色々ありますが、ここでは割愛してぜひ「ゼロから作るDeep Learning」をご参照ください。
まとめ
この記事にまとめたのはあくまでニューラルネットワークの訓練の1案に過ぎないです。活性化関数やロス関数など実際色んな計算方法があります。詳細は是非「ゼロから作るDeep Learning」の本を読んでみてください。ただいま「自然言語処理の基礎」を読んでいますが、この本の2章が機械学習のまとめについて書いていますが、「ゼロから作るDeep Learning」を読んだのでサクサク行けました。代わりに「ゼロから作るDeep Learning」を読んでなかったらなかなか理解できなかったかもなと思います。基礎から勉強するのは大事ですね。そして、この記事を書くために、読んだ本をもう一度振り返って読んだり、微分式を自分で解いてみたりして、一番勉強になったのは私かもしれないなと感じていますが、あくまで自分が理解した内容なので、間違ったところや補足などはぜひ指摘していただければと思います。
機械学習は昔から興味がありますが、なかなかプライベートでその一歩を踏み出せなかったです。今回チームシャフルのお陰でMLEのプロの皆さんと一緒に開発できて要約入門のチャンスができてとても嬉しくて楽しかったです!SWEー>SREやMLEー>SWEなど私のような事例は他にもあります。自分で言うのもあれですが本当に業務時間でも勉強になる最高なエンジニア組織と思います。なので、これから色々分野に触れてみたり、新しい技術を試したりしたい方はぜひ UZABASE へ応募してください。お待ちしております。