こちらの記事は以前にNewsPicks Tech Guideに投稿された記事をインポートしたものです。元の記事はid:satorishによって書かれました。
今回は、QCon NY 2019 初日に行われた、 Time Predictions in Uber Eats セッションの参加レポートです。登壇者は Uber Eats から Zi Wang さんです。

概要
Uber Eats はフードデリバリーサービスです。しかし、配達員はレストランの従業員ではなく、空き時間を利用したい一般人です。配達員は配達すればするほどお金がもらえます。つまり、Uber Eats は、配達員にいかに多くのレストランに向かわせ(多く稼がせ)、いかに料理が冷めないうちに注文者まで届けるか、というところに心血を注いでシステム開発をしています。本セッションは、その中でも予測システムに注目した技術解説です。
ちなみに、UberEats は500都市以上に展開され、22万以上のレストランと契約し、1年間に80億回以上の注文を受けるそうです。

アプリ画面 by AppleStore
料理完成時間予測の難しさ
注文が発生すると下記の画像のような順に情報が処理されます

注文者がメニューを選んで注文すると、レストランに注文が届き、配達員がアサインされ、配達員が料理をピックアップして届けてくれます。注文する側にとっては、料理が30分で届くのか2時間で届くのかは大きく違います。つまり、配達予想時間はオーダーするかしないか判断する非常に重要な情報となります。
一方で、配達時間をシステムが予測することは非常に困難です。配車サービスのノウハウを活かせるはずの Uber Eats でもなお困難だったのは、料理完成時間の予測が難しいからです。その理由は主に下記のようなものです。
- 料理完成時間の真の解をだれも知らない(計測する手段がない)
- 料理完成時間に影響する変数の多くは計測できない(混雑しているか?皆同じ料理をオーダーしているか?コックは何人か?など)
- 店内の情報がデータに残らない(配達員は過去に待たされているか?逆に料理の完成に間に合わなかったか?)
なるべく早く配達員をレストランに向かわせれば良いのでは?と思いますが、そうすると「到着から20分も待たされて、稼げない」「人気の店が Uber Eats のせいでめちゃくちゃ混む」のような副次的な問題が起きてしまいます。Uber Eatsはステークホルダーである 注文者、配達員、レストラン のすべての利益を考えなければなりません。
料理完成時間予測の工夫
料理完成時間予測の精度を向上するためのポイントを、Zi は3つあげました。
1. 特徴量エンジニアリング (Feature Engineering)
機械学習のために、まずはとにかく可能な限り特徴量を集めます。その後、アンサンブル学習を行います。
料理完成時間は正解データがわからないため、下記のようなデータから推論をしています。
特徴量1: 過去データ
レストランごとの平均提供時間など。
特徴量2: コンテキストデータ
- 曜日
- 月
- 季節
- 場所(駅チカはそもそも混む、など)
- 全体のオーダー量
など。
特徴量3: 直近のデータ
直近10分間の平均提供時間など。
特徴量4: 表現学習 (Representation Learning)
また、NLPを使った表現学習も使います。Uber Eats は大量のメニューデータを持っていますから、表現学習をさせてメニューを分類させました。

表現学習(発表資料より)
メニュー分類を特徴量として、推論に活かすことができます。例えばサラダは早い、揚げ物は時間がかかる、ということです。人間も同じことをしているのではないでしょうか。
これは私の推測ですが、語られていない工夫が相当あったのだろうと思います。なぜなら、多くのメニューの名前は凝っていたり、省略があったりするからです。例えば私の気に入っているラーメンは「BAN BAN CHICKEN」ですが、これをラーメンに分類するにはメニュー自体のカテゴリや、お店の分類も必要です。おそらく、検索システムのノウハウをこれに活かしているだと思います。(例えば、"spicy noodle" とアプリで調べると予想に近い結果を得られますが、同様の工夫を感じます。)Food Discovery with Uber Eats がその点に触れています。
特徴量5: スマートフォンセンサ
配達員がレストランに到着してから出発するまでには、重要な情報が多数含まれています。つまり
- 駐車/駐輪してからレストランにつくまでの時間
- レストランで注文を受け取るまで待っている時間
- or 料理が放置されていた時間
- 料理を受け取ってから車にもどるまでの時間
を特徴量に含める必要があります。GPSももちろん使いますが、GPSは誤差が数メートルあるのでこの用途には適しません。そこで Uber Eats は下記を特徴量として活用しています。
- ジャイロセンサ
- Activity Recognition (スマホOSが提供するユーザーのアクティビティ。下図はAndroidの例。)

端末APIが提供する Activity Recognition by Uber Engineering
ユーザーのActivityを分析した結果、下図のように、配達員が駐車に困っているのか、じっと待っているのか、などがブレイクダウンして調べられるようになりました。歩く時間や駐車している時間は短くしようがありませんが、右の図では、待っている時間(濃い橙色)がアルゴリズム最適化によって徐々に少なくなっていることがわかります。

待ち時間のブレイクダウン by Uber Engineering
2. 機械学習モデル
上に述べたような特徴量を用いて、機械学習を行います。モデルには XGBoost を使っています。
XGBoost は Gradient Boosting と Random Forest を組み合わせた教師あり学習です。大雑把に言えば、決定木を構成し、得られた誤差を目的変数として再び決定木を構成し・・・という処理を繰り返すモデルです。発表では他のモデルと比較したのか、ハイパーパラメタをどう決定したのかなど詳細については触れられませんでした。(後述する Michelangelo に組み込まれているので、ヒントはありそうです。)
3. モデルの継続的改善

(発表資料より)
何度も言うようですが、料理完成時間は正解データがありません。そのため、モデルを更新する際に通常行うような、正解データを元にした推論精度比較は行えません。そこで、センサデータなどから計算した(正解に近いであろう)料理完成時間と推論した時間を比較し、そのエラー量の大小でモデルの良し悪しを判断します。(上図)

モデル投入・学習・評価・投入のシステム全体図(発表資料より)
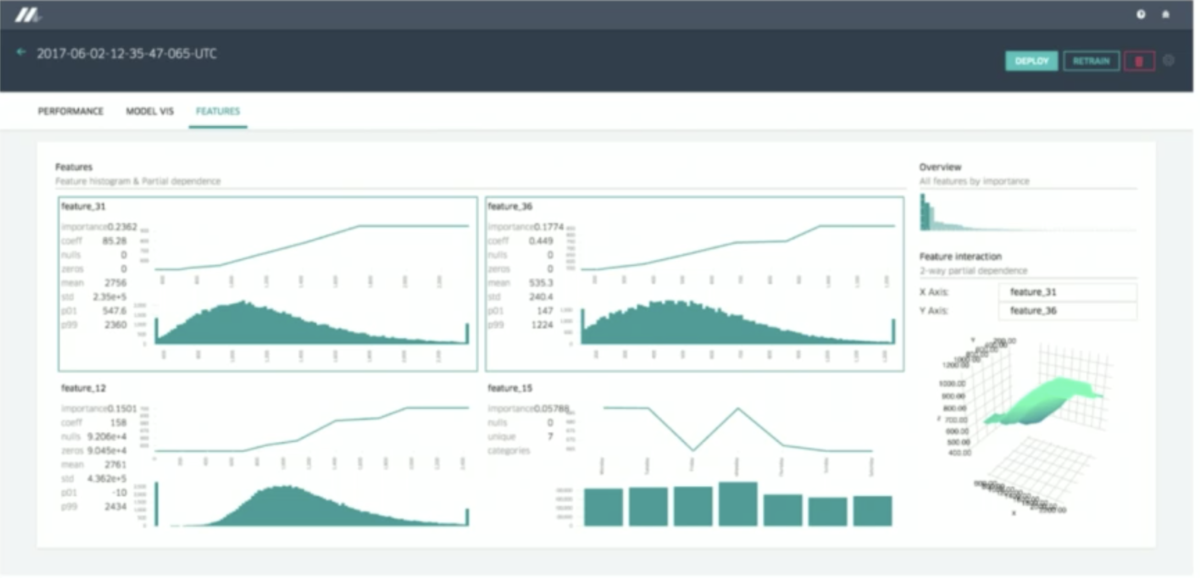
モデル比較ダッシュボード(発表資料より)
機械学習は理論の進化が早く、モデル作成方法に暗黙知が入りがちなため、本番でそこそこうまく機能しているモデルが「腐ってしまう」ことがよくあります。また、モデルを継続的に改善するためには、本番モデルと実験モデルを容易に比較できる環境を整えることが重要です。Uber は Michelangelo という機械学習フレームワークを開発し、モデルを腐らせず常に継続的に改善する基盤を整えています。(上図)新しい特徴量を投入すると、現モデルと更新モデルの比較結果がダッシュボードにわかりやすく表示され、結果が好ましいものであれば、本番へのモデル投入も簡単に行うことができます。
まとめ
Uber Eats は、きめ細かい Feature Engineering と アンサンブル学習、継続的モデル改善によって、正解がわからない料理完成時間を推測しています。これによって注文者は待ち時間にイラつかず、配達員は効率的にレストランをまわり、レストランには過剰な負荷がかからないような工夫がなされています。
余談ですが、ニューヨークではフードデリバリーはとても普及しており、私の住むマンションの入り口でもひっきりなしに配達員を見かけます。その苛烈な競争のなかで、かなり繊細なチューニングを施しているのだろうと思います。そうしないと、利用者の我々から見れば、より良いサービスに乗り換えることはこの上なく簡単だからです。
合わせて読みたい
Uber の歴史、技術戦略、そして日本市場攻略の糸口とは。2018年の記事ですが、今でも読み応えのある記事です。